반응형
파이썬 문자열 함수



실습
text = "hello"
upper_text = text.upper()
print(upper_text)
sentence = 'hello python'
caplitalzed_sentence = sentence.capitalize()
print(caplitalzed_sentence)
title_sentence = sentence.title()
print(title_sentence)
swapped_title_sentence = title_sentence
print(swapped_title_sentence)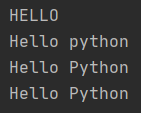
text = ' hello python '
print(text)
print(text.strip())
print(text.rstrip())
print(text.lstrip())
print(text.replace(' ', '.'))
print(text.replace('hello', 'bye'))
text = 'hello python'
print(text)
print(text.split())
print(text.split('p'))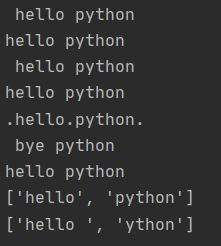
test = '1,62,7,543,12\n'
split_test = test.strip().split(',')
print(split_test)
print(list(map(int, test.strip().split(','))))
join_split_test = ','.join(split_test)
print(join_split_test)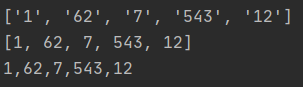
test1 = 'hello python\n this is nlp tutorial\n string function ex\n'
print(test1)
print(test1.splitlines())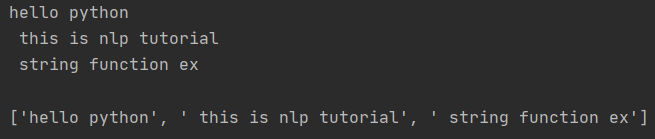
text = '123'
print(text.isdigit())
text = 'abc'
print(text.isalpha())
text = '1a2b3c'
print(text.isdigit())
print(text.isalpha())
print(text.isalnum())
text = 'hello'
print(text.islower())
print(text.isupper())
text = 'HELLO'
print(text.islower())
print(text.isupper())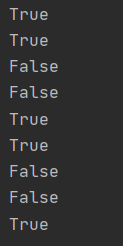
text = 'hello'
print(text.startswith('h'))
print(text.endswith('o'))
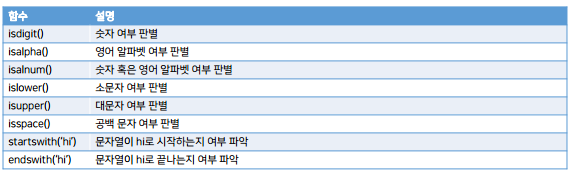
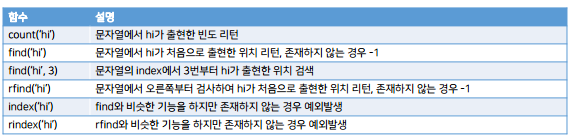
text = 'hi1 hi2 hi3 hi4'
print(text.count('hi'))
print(text.find('hi'))
print(text.find('hi', 1))
print(text.rfind('hi'))
print(text.find('hi5'))
print(text.index('hi'))
#print(text.index('hi5'))
print(text.index('hi5'))
→ hi5 라는 string을 찾을 수 없어서 오류가 남
정규표현식
- 복잡한 문자열을 처리할 때 사용하는 기법
- 파이썬만의 고유 문법이 아니라 문자열을 처리하는 모든 곳에서 활용
- re라는 모듈 사용
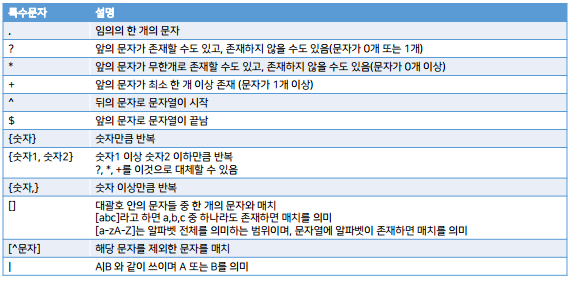
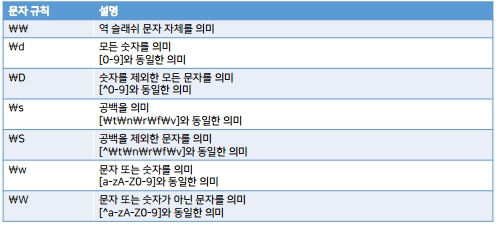
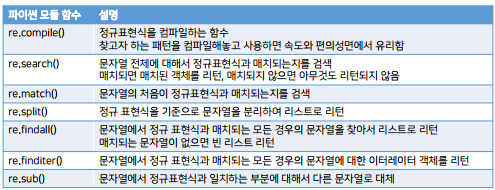
\b : 단어의 경계(word boundary) 문자자체라서 \하나를 더 써야한다.
정규표현식 실습
import re
# . 한 개의 임의의 문자
r = re.compile("a.c")
print(r.search("abd"))
print(r.search("abc"))
# ? 앞의 문자가 존재 or 미존재
r = re.compile("abc?")
print(r.search("abc"))
print(r.search("ab"))
# * 앞의 문자가 0개 이상
r = re.compile("ab*c")
print(r.search("ac"))
print(r.search("abc"))
print(r.search("abbbc"))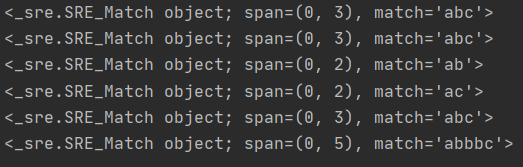
# + 앞의 문자가 1개 이상
r = re.compile("ab+c")
print(r.search("ac"))
print(r.search("abc"))
print(r.search("abbbc"))
# ^ 시작되는 글자를 지정
r = re.compile("^bc")
print(r.search("abc"))
print(r.search("bc"))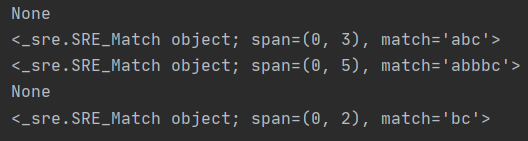
# {숫자} 해당 문자를 숫자만큼 반복
r = re.compile("ab{2}c")
print(r.search("abc"))
print(r.search("abbc"))
print(r.search("abbbc"))
# {숫자1, 숫자2} 해당 문자를 숫자1 이상, 숫자2 이하만큼 반복
r = re.compile("ab{2,4}c")
print(r.search("abc"))
print(r.search("abbc"))
print(r.search("abbbc"))
print(r.search("abbbbc"))
print(r.search("abbbbbc"))
# {숫자,} 해당 문자를 숫자 이상 만큼 반복
r = re.compile("ab{2,}c")
print(r.search("abc"))
print(r.search("abbc"))
print(r.search("abbbc"))
print(r.search("abbbbc"))
print(r.search("abbbbbc"))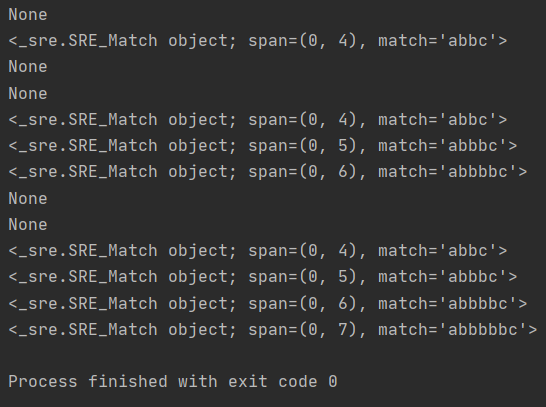
# [문자] 문자들 중 한개의 문자와 매치
# [a-zA-Z]는 알파벳 전부를 의미, [0-9]는 숫자 전부를 의미
r = re.compile("[abc]")
print(r.search("a"))
print(r.search("d"))
# [^문자] 제외한 모든 문자를 매치
r = re.compile("[^ac]")
print(r.search("a"))
print(r.search("d"))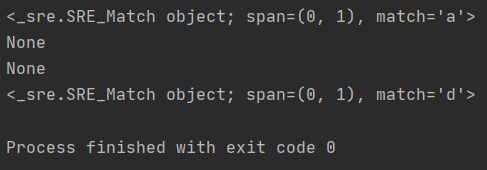
정규표현식 실습2
##### 숫자로만 이루어진 단어를 찾아서 반환 #####
sentence = '1 star lstar 4 dollar 4doller 10 people 10people'
# coding
# 1, 4, 10 결과로 반환하도록
r = re.compile("\\b[0-9]+\\b")
result = r.findall(sentence)
print(result)
## 92년생 찾기 ###
def get_years_92(birthdays):
r = re.compile('92[0-9]{4}')
result = []
# coding
for birth in birthdays:
if r.match(birth):
result.append(birth)
return result
def get_years_92_function(birthdays):
result = []
# coding
for birth in birthdays:
if birth.startswith('92'):
result.append(birth)
return result
birthdays = ['911211', '920109', '930205', '941124', '900502', '920412', '931121', '940608', '950926']
print(get_years_92(birthdays))
print(get_years_92_function(birthdays))
### 뉴스 기사에서 이메일 주소 찾기 ###
news = '기사제목\n기사본문\nhello@chosun.com\n2020-09-08\n'
r = re.compile('[a-zA-Z0-9]+@[a-zA-Z0-9]+\.com')
result = r.search(news)
print(result)
print(result.group())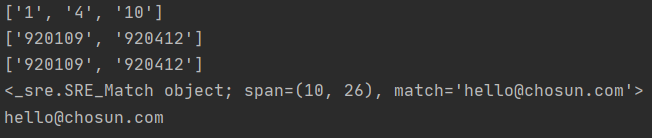
* String 만 나오게 하는 방법 *
- result.start() 또는 result.end() 함수를 활용해서 시작위치랑 끝 위치를 받아와서 news[result.start():result:end()] 출력
- result.group() 함수 호출
반응형
'프로그래밍 언어 > Python' 카테고리의 다른 글
| [Python] 라이브러리 다운로드 에러 (0) | 2020.09.27 |
|---|---|
| [Python] 파이썬-파이참 설치하기 (0) | 2020.09.27 |