최신모델 State of the art Models
Transformers
- BERT랑 GPT의 기반이 되는 네트워크
- Seq2seq 모델을 약간 보정하기 위해 나온 것
- Seq2seq model에서는 전체 Context 가 한번에 넘겨가지는 못하고, Attention이 있다고 하더라도 굳이 하나씩 보지말고 전체를 한번에 볼 수 있을까? 해서 만든 것이 Transformers Network
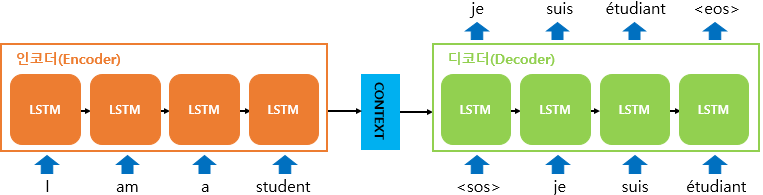
Seq2seq model
- seq2seq 모델은 인코더-디코더 구조로 되어있음
- 인코더는 입력 시퀀스를 하나의 벡터 표현으로 압축하고, 디코더는 이 벡터 표현을 통해서 출력 시퀀스를 생성

그렇다면 Attention으로 RNN을 보정하지 않고, 인코더 디코더안에 Attention을 넣어버린다면??
→ 트랜스포머 네트워크
Transformers Network
- 트랜스포머 하나에 인코더와 디코더가 다 들어가있음 → 전체 입력이 트랜스포머 하나에 다 들어감

→ lstm이 느려서 그냥 인코더, 디코더 안에 Attention을 넣어버림
Transformers Network
- 논문 (Attention is all you need. Vaswani et al. 2017) → 꼭 읽어봐야함
- 구글 연구 팀이 공개한 딥러닝 아키텍쳐로 뛰어난 성능으로 주목 받았음
- GPT, BERT 등의 모델의 기본 모델로 활용되고 있음
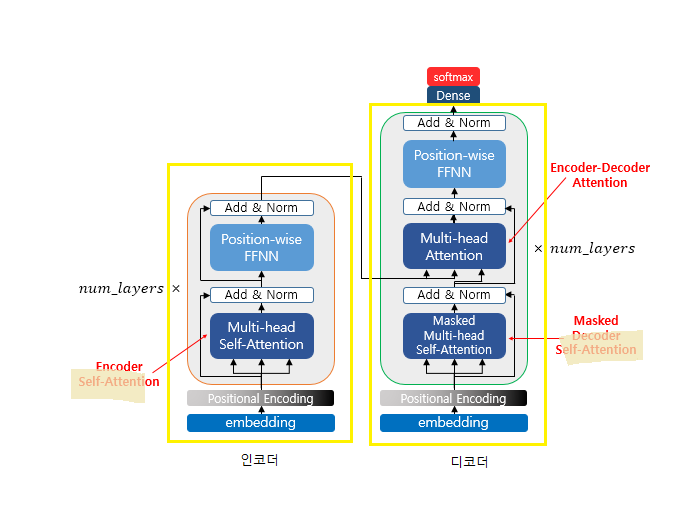
→ 인코더에도 디코더에도 임베딩을 전체를 넣어버리고, 인코더에서 애초에 Attention을 활용해서 인코더 전체에 대한 Self-Attention을 보고, 디코더에서도 디코더 전체에 대한 Self-Attention을 알아서 한번 본 다음에 인코더 디코더를 합친 Attention을 가지고 뭔가 하나를 분류하는 거
→ 인코더 디코더를 Layer를 여러개를 쌓을 때 층을 위에 계속 올린다
인코더 : 셀프 어텐션을 거치고 FeedForward 신경망(DNN)을 거쳐서 디코더로 보내줌
ADD : 원래값과 Attention을 거친 값을 넣어서 합한다음 Norm을 해준다 (Overfitting이 줄어듬)
FFNN (Feed Forward Network) : DNN - 매 token마다 아웃풋이 나옴
residual connection : FFNN을 안거치고 바로 ADD로 이동하는 부분
Transformers Network의 구조를 숙지해야 자연어처리를 할 수 있음
Positional Encoding
- Transformer는 한번에 입력하다보니 lstm처럼 순서를 알수가 없음
→ lstm같은 경우에는 순서까지 고려되서 모델 생성이 되는데 트랜스포머 네트워크는 순서를 알수 없어서 순서를 알려주려고 하는 부분이 포지셔널 인코딩임 - 트랜스포머는 단어 입력을 순차적으로 받는 방식이 아니므로, 단어의 위치 정보를 다른 방식으로 알려줄 필요가 있음
- 각 단어의 임베딩 벡터에 위치 정보들을 더하여 모델 입력으로 사용하며, 이를 포지셔널 인코딩이라 함
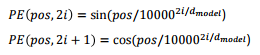
→ 위치가 2의 배수일 때는 sin 함수, 위치가 홀수일 때는 cos 함수를 해서 값을 더해줌

→ 포지셔널 인코딩에는 이와 같은 함수를 활용하여 위치 정보를 생성
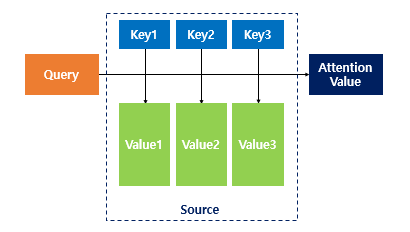
셀프 어텐션 (Self Attention)
- Key, Value, Query 값이 모두 같은 경우
멀티헤드 어텐션 (Multi-head Attention)
- multi-head는 어텐션을 head 개수만큼 병렬로 수행하는 방법
트렌스포머의 어텐션 3가지
- 3가지의 어텐션이 활용됨
- Encoder Self-Attention : Query = Key = Value
각 attention은 multi-head attention이 적용이 되어 있음 !! 실제 transfomer의 attention은 dot product attention이 적용되어 있어서 그냥 matrix 곱셈 연산 정도만 수행한다고 생각하쟈
https://github.com/jadore801120/attention-is-all-you-need-pytorch/blob/master/transformer/Models.py
→ 트랜스포머 모델 구현하는 소스코드
GPT
- (Improving language understanding by generative pre-training. Radford, Alec, et al. 2018)
- Transformer의 디코더를 적층한 모델
- 디코더를 활용하여, 생성 모델에 적합
- Transformer를 활용한 pre-trained model의 시초
GPT 학습 방식
- 일반적인 Language Model(언어 모델) 학습 방식을 활용하여, 대용량 코퍼스를 활용한 비지도 학습
GPT는 꽤 괜찮은 성능을 보여줬지만 전반적으로 성능이 엄청 좋지는 않음,, 기존의 모델들 보다는 우수한 성능을 내는것도 있고, 모자란 것도 있고, 비슷한 것도 있음
BERT
- (BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Devlin et al. 2018)
- Transformer의 인코더를 적층해서 맨 뒤에 Layer 하나만 붙임 (Fine-Tuning)
- 잘 만들어진 BERT 언어모델 위에 1개의 classification layer만 부착하여 다양한 NLP task를 수행
- 영어권에서 11개의 NLP task에 대해 state-of-the-art (SOTA) - 전부 최신성능 달성 !!
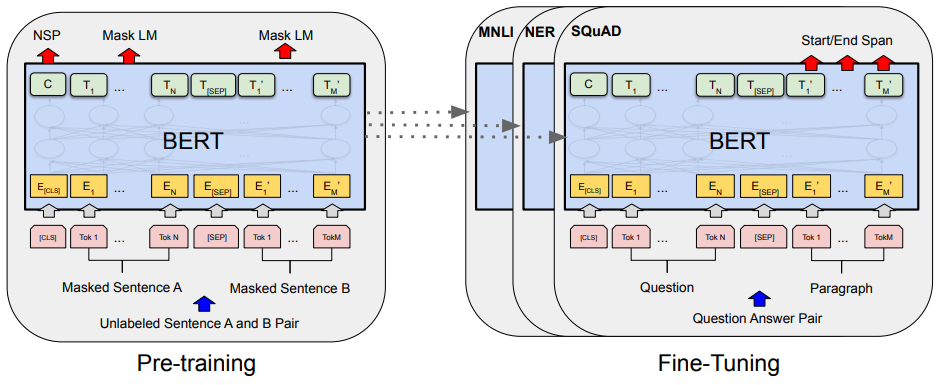
→ 인코더를 쌓고나서 원래 BERT는 Mask LM이랑 NSP 두가지를 학습을 했었는데 BERT Fine-Tuning은 여기에다가 Layer를 하나만 추가를 함,,
→ 원래 트랜스포머 인코더가 12개가 안에 적층이 쌓여있음! 근데 여기에다가 분류를 할때는 Classification Layer를 하나 추가해주고, 기계독해를 할때는 정답의 위치를 출력하는 Layer 추가해주고, 개체명인식은 각 토큰마다 벡터가 나오기 때문에 각 토큰마다 tagging 을 하도록 Layer를 추가함
BERT 학습 방식
BERT 이전의 GPT는 기존의 Language Model(언어 모델)을 그대로 학습을 함 → 각 토큰 순서대로 예측을 함
MLM (Masked Language Model)
- 무슨 토큰이 나와야 할지 분류 !
- 입력 문장에서 임의로 토큰을 masking 한 후에, 해당 토큰을 맞추는 학습
→ 토큰 하나하나 학습을 안하니까 학습 속도도 빠르고, 인코더를 사용하니까 lstm처럼 이전 토큰에 대한 연산을 기다리지 않아도 된다. lstm 층을 많이 쌓으면 엄청 느린데 BERT는 훨씬 빠르다.
→ 층을 아무리 쌓아도 lstm만큼 느려지지 않음
BERT에서는 Transformer Incoder를 기본적으로 12개 층을 쌓아서 만들었음
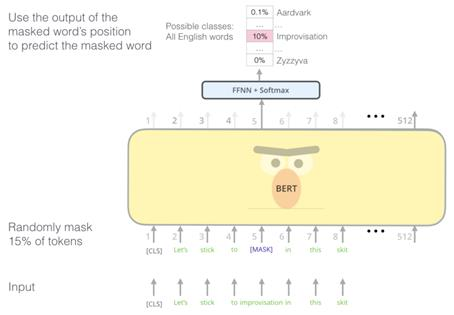
NSP (Next Sentence Prediction)
- 두 문장이 주어졌을 때, 두 문장의 순서를 예측하는 방식
- 순서가 맞는지 틀렸는지를 학습함
- 학습데이터를 문서단위로 입력할 때 문서에서 다음 문장을 가지고 왔을 때는 1, 문장의 순서를 랜덤으로 바꾸고 가지고 올 때는 0으로 학습
→ Bi-classification만 학습을 하기 때문에 학습속도가 빠름
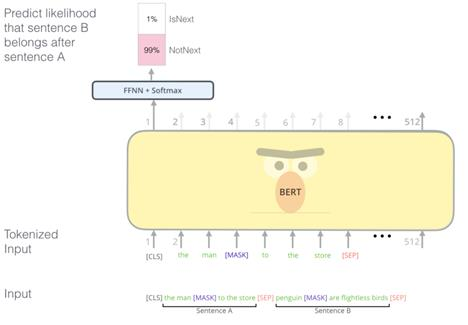
BERT vs GPT vs ELMo
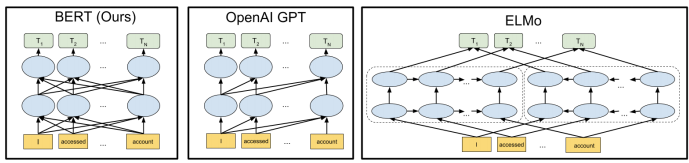
- BERT - 구글에서 만듬
- MLM학습으로 인하여, 동시에 연산이 가능 → 속도가 빨라짐
- GPT - OpenAI에서 만듬
- Transformer의 디코더만 사용 - 언어모델 사용
- LM(언어모델) 학습으로 인하여 결국 lstm처럼 앞의 토큰 예측이 끝나야 다음 토큰 예측 가능
→ BERT보다 속도는 훨씬 느림
BERT 이후의 모델들
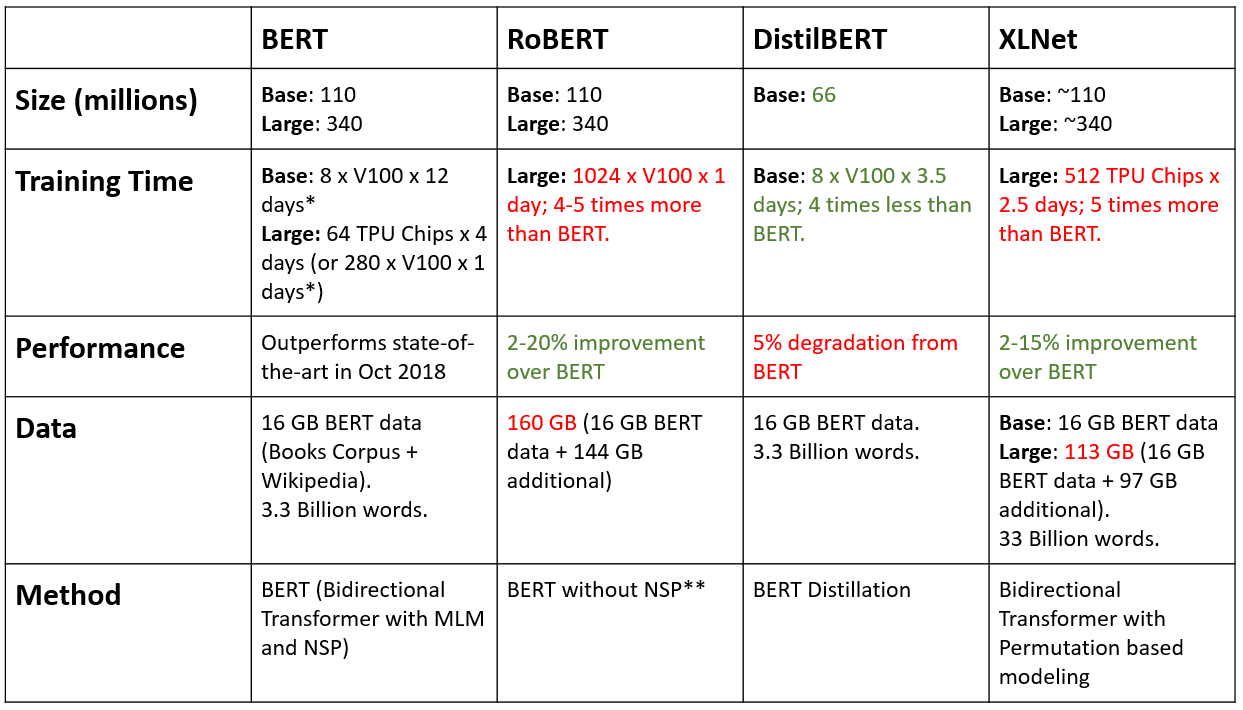
- BERT랑 RoBERT랑 차이가 별로 없음, 학습 파라미터 갯수(Size)가 똑같음
→ BERT는 GPU를 기준으로 V100을 8대를 12일동안 학습함, RoBERT는 1024개의 GPU를 붙여서 하루만에 학습함
→ 학습을 하면서 데이터를 정말 많이 늘렸고, NSP 을 빼고 학습을 함 - DistilBERT : BERT에서 뭔가를 없앤것
→ BERT가 네트워크 Layer수를 많이 쌓으면서 많이 느린 문제 때문에 Layer를 12개를 사용하는데 Layer를 줄여서 속도를 빠르게 만듬
→ 다른거는 똑같음 (모델 사이즈를 줄임 110 → 66)
→ 성능이 조금 떨어졌지만 속도가 빨라짐 - XLNet (permutation??순열??) 학습방법을 바꿈
- BERT의 MLM 학습에서는 masking된 토큰이 여러개일 때, 하나의 토큰을 예측할 때 다른 토큰도 masking 되어있다.
- XLNet 학습방법 - 처음 앞에 있는 토큰을 예측할 때는 두개의 토큰이 다 masking 되어 있지만 , 뒤의 토큰을 예측할 때는 앞에서 예측한 결과를 받아와서 활용함
- LSTM이나 GPT 처럼 순서가 생기는 문제때문에 학습 속도가 느려짐
최신 모델들
최신모델 실습
https://github.com/huggingface/transformers
→ transformer기반의 최신 모델들의 쉽게 사용할 수 있도록 제공하는 라이브러리
→ transformers 라이브러리 쓸 때는 pytorch 사용하는 것을 권장
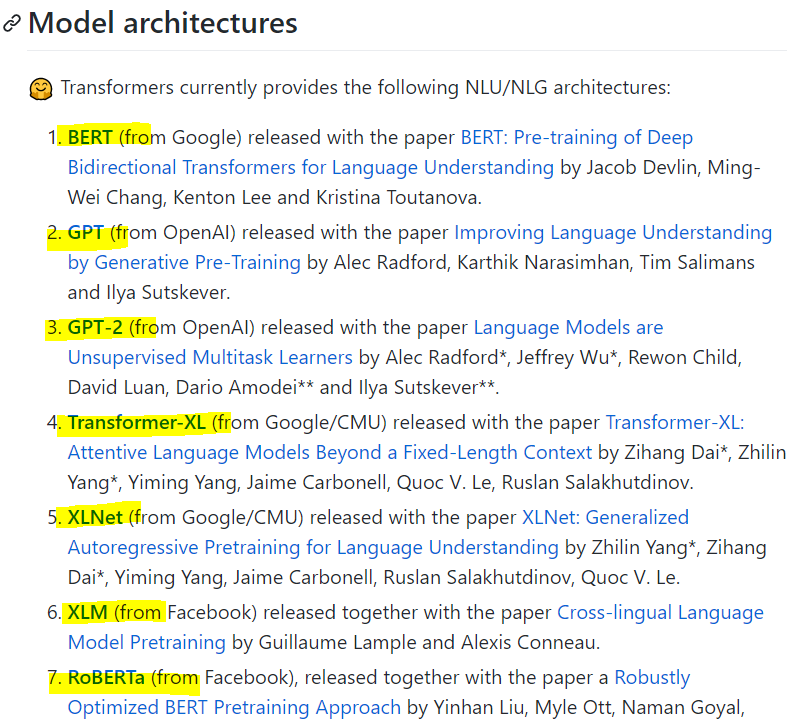
→ transformer기반의 모델이 엄청 많음
→ GPT가 시초임
!pip install transformers
from transformers import GPT2Tokenizer, GPT2Model
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2Model.from_pretrained('gpt2')text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
print(output)
→ output이 숫자로 나오는데 나중에 반대로 다시 token으로 바꿔주면 끝 !!
→ token으로 바꿔주는 예제는 찾아보면 있을듯,,,
https://github.com/huggingface/transformers/tree/master/notebooks
→ colab으로 바로 실행할 수 있는 링크
https://github.com/huggingface/transformers/blob/master/examples/text-generation/run_generation.py
→ 서버가 셋팅이 되면 이걸 실행해봐도 됨
https://www.tensorflow.org/official_models/fine_tuning_bert
→ tensorflow를 활용해서 어떻게 해야하는지에 대한 설명부터 가이드가 다 있음
→ tensorflow를 활용해서 BERT 모델을 다운로드 받아서 BERT 모델을 가지고 어떻게 학습을 하는지까지 다 나와있음
→ colab에서 실행을 누르면 코드 그대로 colab으로 넘어옴 (colab은 번역이 안됨)
'AI > 자연어처리' 카테고리의 다른 글
| [AI] BPE (Byte Pair Encoding) 설명 및 예제 (0) | 2020.12.18 |
|---|---|
| [AI] StanfordNLP, Khaiii (Kakao Hangul Analyzer III) 설명 및 예제 (0) | 2020.12.18 |
| [AI] 어텐션 메커니즘(Attention Mechanism)이란? - 개념 및 예제 (0) | 2020.12.17 |
| [AI] Annoy (Approximate Nearest Neighbors Oh Yeah) 설명 및 예제 (0) | 2020.12.17 |
| [AI] Embedding + LSTM 분류 예제 (0) | 2020.12.16 |