반응형
임베딩에 관련된 설명 및 예제 참고 ↓
[AI] Word2Vec, GloVe, FastText, ELMo 기본 설명 및 실습
Embedding + LSTM 분류 실습
- 초반에 LSTM 분류를 원핫인코딩으로 했던걸, 글로브 벡터 입력으로 받도록 해서 수정
from collections import Counter
import urllib.request # spam 메일 데이터 받아오려고 씀
import pandas as pd
import numpy as np
import tensorflow as tf
import nltk
from nltk.tokenize import sent_tokenize
from nltk import WordPunctTokenizer
nltk.download('punkt')from google.colab import drive
drive.mount('/content/drive')# spam classification data loading : 스팸 분류 데이터 로딩
urllib.request.urlretrieve("https://raw.githubusercontent.com/mohitgupta-omg/Kaggle-SMS-Spam-Collection-Dataset-/master/spam.csv", filename="spam.csv")
data = pd.read_csv('spam.csv', encoding='latin-1')
data[:5]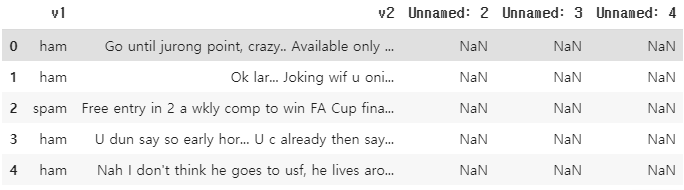
texts = list(data['v2'])
labels = list(data['v1'])
print(texts[:5])
print(labels[:5])
print(Counter(labels)) # ham 갯수, spam 갯수 출력
- glove 벡터 불러오기 → 구글 드라이브에 올려서 가져오기
# glove vector model initialize : 글로브 벡터 모델 초기화
glove = {}
with open('/content/drive/My Drive/Colab Notebooks/data/news_sample/glove.6B.50d.txt', 'r', encoding='utf-8') as fr:
for line in fr.readlines():
temp = line.strip().split()
word = temp[0]
vector = temp[1:]
glove[word] = list(map(float, vector))
- get_vector 함수
- 문장을 받아서 tokenize를 해주고 token마다 돌면서 이 토큰이 glove 벡터 모델에 있으면 glove에서 벡터 모델을 가지고 오고, 없으면 0 *50 개를 넣는다.
def tokenize(document):
words = []
# sentence tokenizing : 구문을 문장 단위로 분리
sentences = sent_tokenize(document)
for sentence in sentences:
words.extend(WordPunctTokenizer().tokenize(sentence)) # word tokenizing
return [word.lower() for word in words] # case normalization : 표준화
def get_vector(sentence):
tokens = tokenize(sentence)
vector = [glove[token] if token in glove.keys() else [0]*50 for token in tokens]
while len(vector) < 256:
vector.append([0] * 50)
return vector[:256]
- texts들을 벡터로 다 가지고 오게 함!
- 5000개 기준으로 나눠서 numpy로 감싸줌
- y는 labels가 spam이랑 ham이 있기때문에 spam일 때는 0, 아닐때는 1
- y도 마찬가지로 5000개를 기준으로 나눠줌
x = [get_vector(text) for text in texts]
x_train, x_test = np.array(x[:5000]), np.array(x[5000:])
y = [0 if label == 'spam' else 1 for label in labels]
y_train, y_test = np.array(y[:5000]), np.array(y[5000:])
- 분류를 2가지로 분류하기 때문에 softmax를 2로 줌
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Input(shape=(x_train.shape[1], x_train.shape[2])))
model.add(tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(128)))
model.add(tf.keras.layers.Dense(64, activation = 'relu'))
model.add(tf.keras.layers.Dense(2, activation = 'softmax'))
model.summary()
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(x_train, y_train, epochs=2)
model.evaluate(x_test, y_test, verbose=2)
glove가 word2vec 중에서 제일 학습이 잘되있고 성능이 잘나오다보니 glove랑 lstm을 가지고 문장을 분류하는 것을 굉장히 많이 활용이 된다.
→ 지금은 BERT를 많이 이용한다.
반응형
'AI > 자연어처리' 카테고리의 다른 글
| [AI] 어텐션 메커니즘(Attention Mechanism)이란? - 개념 및 예제 (0) | 2020.12.17 |
|---|---|
| [AI] Annoy (Approximate Nearest Neighbors Oh Yeah) 설명 및 예제 (0) | 2020.12.17 |
| [AI] Word2Vec, GloVe, FastText, ELMo 기본 설명 및 실습 (0) | 2020.12.16 |
| [AI] 단어표현방법 (Bag of Words, Word2Vec, One-hot Vector 등) 설명 및 실습 (1) | 2020.12.15 |
| [AI] 벡터화 및 One-Hot Encoding 실습 (0) | 2020.11.27 |