반응형
어텐션 메커니즘 (Attention Mechanism)
- seq2seq 모델의 문제점 : 전체 문장에 대해서 context를 단 한 번에 넘겨줌
- 매 순간마다 데이터를 다 넣어주기 위해 사용
Seq2seq model
- 전체 문장에 대한 정보를 한꺼번에 벡터 하나로 만들어서 넘겨주니까 token에서의 정보는 하나도 안 남아있고, 전체 문장에 대한 Context만 넘어감
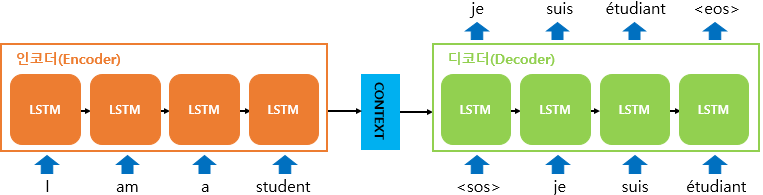
Attention은 Seq2seq model을 보완하고자 만든 것
Attention
- 쿼리에 대해서 모든 키와의 유사도를 각각 구하고, 유사도를 키와 맵핑되어 있는 각각의 value에 반영
- Query : t 시점의 디코더 셀에서의 은닉 상태
- Keys : 모든 시점의 인코더 셀의 은닉 상태
- Values : 모든 시점의 인코더 셀의 은닉 상태
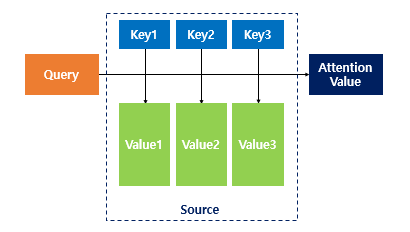
→ Attention Value는 Query랑 Key가 들어가서 Value가 곱해져서 다 합쳐진 거임 (먼 소리야ㅎㅎ,,)
Dot-product Attention
- 매 순간마다 앞에 있던 것을 다 같이 보겠다는 것
- 기본적으로 곱하기임

→ softmax Layer에서 더 연관이 있는 단어에 weight를 더 많이 줘서 weight들을 전부 더해서 다음에 나올 단어를 예측한다.
그 외의 Attention 종류들

Attention 실습
- 전에 만들었던 glove_lstm_classification.ipynb 에 attention을 추가해서 만듬
- 다른 거는 똑같고, model 쪽에 attention 추가
from collections import Counter
import urllib.request
import pandas as pd
import numpy as np
import tensorflow as tf
import nltk
from nltk.tokenize import sent_tokenize
from nltk import WordPunctTokenizer
nltk.download('punkt')from google.colab import drive
drive.mount('/content/drive')# spam classification data loading
urllib.request.urlretrieve("https://raw.githubusercontent.com/mohitgupta-omg/Kaggle-SMS-Spam-Collection-Dataset-/master/spam.csv", filename="spam.csv")
data = pd.read_csv('spam.csv', encoding='latin-1')
data[:5]texts = list(data['v2'])
labels = list(data['v1'])
print(texts[:5])
print(labels[:5])
print(Counter(labels))# glove vector model initialize
glove = {}
with open('/content/drive/My Drive/Colab Notebooks/data/news_sample/glove.6B.50d.txt', 'r', encoding='utf-8') as fr:
for line in fr.readlines():
temp = line.strip().split()
word = temp[0]
vector = temp[1:]
glove[word] = list(map(float, vector))def tokenize(document):
words = []
sentences = sent_tokenize(document) # sentence tokenizing
for sentence in sentences:
words.extend(WordPunctTokenizer().tokenize(sentence)) # word tokenizing
return [word.lower() for word in words] # case normalization
def get_vector(sentence):
tokens = tokenize(sentence)
vector = [glove[token] if token in glove.keys() else [0]*50 for token in tokens]
while len(vector) < 256:
vector.append([0] * 50)
return vector[:256]x = [get_vector(text) for text in texts]
x_train, x_test = np.array(x[:5000]), np.array(x[5000:])
y = [0 if label == 'spam' else 1 for label in labels]
y_train, y_test = np.array(y[:5000]), np.array(y[5000:])
- 모델 생성
- tf.keras.layers.LSTM(128) → 자동으로 LSTM이 다대일로 해서 제일 마지막 결과만 여기 layer에서 출력해준다.
- (tf.keras.layers.LSTM(128, return_sequences=True))
→ 모든 칸에 대해서 반환 - Query밖에 없고 Key와 Value가 필요한 경우
→ 세 개를 똑같은걸 넣어줄 때 salf-attention이라고 함 - tf.keras.layers.Attention()([lstm_layer, lstm_layer, lstm_layer])
→ 원래는 Query, Key, Value 순서대로 넣어야 되는데 지금 Query 하나밖에 없기 때문에 똑같은 거를 넣어줌,, 이거를 salf-attention이라고 함
input_layer = tf.keras.layers.Input(shape=(x_train.shape[1], x_train.shape[2]))
lstm_layer = tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(128, return_sequences=True))(input_layer)
attention = tf.keras.layers.Attention()([lstm_layer, lstm_layer, lstm_layer])
flatten = tf.keras.layers.Flatten()(attention)
dense1_layer = tf.keras.layers.Dense(64, activation = 'relu')(flatten)
dense2_layer = tf.keras.layers.Dense(2, activation = 'softmax')(dense1_layer)
model = tf.keras.Model(inputs=input_layer, outputs=dense2_layer)model.summary()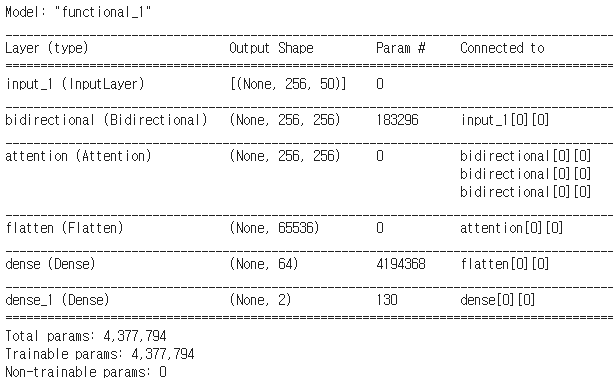
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(x_train, y_train, epochs=2)
model.evaluate(x_test, y_test, verbose=2)
glove 벡터를 가지고 넣어줬는데 모델 자체에 embedding Layer를 추가할 수 있음! 그럼 vocabulary 아이디만 넣어주고 모델을 활용할 수 있음
Embedding + lstmm + attention 분류 실습 - embedding_layer_lstm_attention_classification.ipynb
from collections import Counter
import urllib.request
import pandas as pd
import numpy as np
import tensorflow as tf
import nltk
from nltk.tokenize import sent_tokenize
from nltk import WordPunctTokenizer
nltk.download('punkt')# spam classification data loading
urllib.request.urlretrieve("https://raw.githubusercontent.com/mohitgupta-omg/Kaggle-SMS-Spam-Collection-Dataset-/master/spam.csv", filename="spam.csv")
data = pd.read_csv('spam.csv', encoding='latin-1')
data[:5]texts = list(data['v2'])
labels = list(data['v1'])
print(texts[:5])
print(labels[:5])
print(Counter(labels))
- vocab을 만드는 코드 생성
- vector는 vocab이라는 것을 받아서 vocab에 있으면 vocab에 token ID 만 줄 거임, 없을 때는 vocab에 unk을 넣어서 줄거임
- vector가 256보다 작을 때는 <pad>라고 줄 거임
def tokenize(document):
words = []
sentences = sent_tokenize(document) # sentence tokenizing
for sentence in sentences:
words.extend(WordPunctTokenizer().tokenize(sentence)) # word tokenizing
return [word.lower() for word in words] # case normalization
def make_vocab(documents):
word2index = {'<unk>':0, '<pad>':1}
for document in documents:
tokens = tokenize(document)
for token in tokens:
if token not in word2index.keys():
word2index[token] = len(word2index)
return word2index
def get_vector(sentence, vocab):
tokens = tokenize(sentence)
vector = [vocab[token] if token in vocab.keys() else vocab['<unk>'] for token in tokens]
while len(vector) < 256:
vector.append(vocab['<pad>'])
return vector[:256]
- vocab을 어떻게 만들었는지 확인, tokenize에 있는 결과 확인, vector 결과 확인
vocab = make_vocab(texts)
print(vocab)
print(texts[0])
print(tokenize(texts[0]))
print(get_vector(texts[0], vocab))
→ get_vector(texts[0], vocab) : 19까지는 ID가 있고 나머지 뒤에 1들은 pad가 채워짐 (256보다 짧기 때문에)
- x_train = 5000 * 256
x = [get_vector(text, vocab) for text in texts]
x_train, x_test = np.array(x[:5000]), np.array(x[5000:])
y = [0 if label == 'spam' else 1 for label in labels]
y_train, y_test = np.array(y[:5000]), np.array(y[5000:])
print(x_train.shape)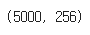
- 256개의 token에 대해서 embedding Layer가 붙어야 함
- tf.keras.layers.Embedding(len(vocab), 100) → 100 : 사이즈 → 임베딩 테이블이 word2vec랑 똑같이 생김 → 각 vocab에 대해서 100차원짜리 임베딩 테이블 생성
- tf.keras.layers.Dropout(0.5)(embedding_table(input_layer)) → 임베딩 테이블에 input이 들어가서 dropout
- 이렇게 만들면 glove 벡터를 따로 불러서 넣어줄 필요 없이 자체적으로 word2vec 모델을 안에 내장해버림,, → word2vec 모델도 실시간으로 같이 한꺼번에 학습됨! 학습 속도는 느려질 수 있음
input_layer = tf.keras.layers.Input(shape=(x_train.shape[1]))
embedding_table = tf.keras.layers.Embedding(len(vocab), 100)
embedded_layer = tf.keras.layers.Dropout(0.5)(embedding_table(input_layer))
lstm_layer = tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(128, return_sequences=True))(embedded_layer)
attention = tf.keras.layers.Attention()([lstm_layer, lstm_layer, lstm_layer])
flatten = tf.keras.layers.Flatten()(attention)
dense1_layer = tf.keras.layers.Dense(64, activation = 'relu')(flatten)
dense2_layer = tf.keras.layers.Dense(2, activation = 'softmax')(dense1_layer)
model = tf.keras.Model(inputs=input_layer, outputs=dense2_layer)model.summary()
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(x_train, y_train, epochs=2)
model.evaluate(x_test, y_test, verbose=2)
반응형
'AI > 자연어처리' 카테고리의 다른 글
| [AI] BPE (Byte Pair Encoding) 설명 및 예제 (0) | 2020.12.18 |
|---|---|
| [AI] StanfordNLP, Khaiii (Kakao Hangul Analyzer III) 설명 및 예제 (0) | 2020.12.18 |
| [AI] Annoy (Approximate Nearest Neighbors Oh Yeah) 설명 및 예제 (0) | 2020.12.17 |
| [AI] Embedding + LSTM 분류 예제 (0) | 2020.12.16 |
| [AI] Word2Vec, GloVe, FastText, ELMo 기본 설명 및 실습 (0) | 2020.12.16 |