반응형
단어표현방법(word representation)
- DTM: Document-Term Matrix (문서 단어 행렬)
- LSA: Latent Semantic Analysis (잠재 의미 분석)

- N-gram : N(숫자)가 2라면 2글자씩 토큰으로 만든다.
- Glove : Count랑 Word2Vec이랑 합친것
- LSA : 문서 전체에서 count하는 방법
Bag of Words (BoW)
- 단어들의 순서는 전혀 고려하지 않고, 단어들의 출현 빈도를 활용하는 단어 표현 방법
- 단어들의 가방이라는 뜻으로 모든 단어를 가방에 넣어서 표현한다는 의미
- BoW를 만드는 과정
- 각 단어에 고유한 정수 인덱스를 부여
→ one hot vector에서 처음에 vocab을 생성했던 부분과 동일 - 각 인덱스의 위치에 단어 토큰의 등장 횟수를 기록한 벡터를 생성
- 각 단어에 고유한 정수 인덱스를 부여

Bag of Words 실습
- 형태소 분석기 활용
!pip install konlpy
from konlpy.tag import Kkma
import nltk
from nltk.tokenize import sent_tokenize
nltk.download('punkt')
class Tokenizer:
def __init__(self):
self.kkma = Kkma()
def make_vocab(self, documents):
word2index = {'<unk>':0}
for document in documents:
tokens = self.tokenize(document)
for voca in tokens:
if voca not in word2index.keys(): # voca가 key 리스트에 없으면 리스트에 추가
word2index[voca] = len(word2index)
self.vocab = word2index
# 형태소 분석
def tokenize(self, document):
morphs = []
sentences = sent_tokenize(document)
for sentence in sentences:
sentence_morphs = self.kkma.pos(sentence)
morphs.extend([morph[0] + '/' + morph[1] for morph in sentence_morphs])
print(morphs)
return morphs
# BOW
def bag_of_words(self, sentence):
morphs = self.tokenize(sentence)
vector = [0] * len(self.vocab)
for morph in morphs:
if morph not in self.vocab.keys():
morph = '<unk>'
vector[self.vocab[morph]] += 1
return vector→ 형태소 분석까지 다 한 다음
tokenizer = Tokenizer()
texts = ['안녕하세요', '안녕하십니까', '오늘은 날씨가 좋네요', '기분이 좋아요']
tokenizer.make_vocab(texts) # texts 리스트로 vocab을 만듬
print(tokenizer.vocab) # vocab 출력
tokenizer.bag_of_words('오늘은 날씨가 어떨 것 같으세요') # 문장의 벡터가 됨
→ 0 인덱스의 unk : 5개 , 6 인덱스의 '오늘' : 1개 , 7 인덱스의 '은' : 5개 , 8 인덱스의 '날씨' : 1개 , 9 인덱스의 '가' : 1개
DTM (Document Term Matrix)
- 다수의 문서에서 등장하는 각 단어들의 빈도를 행렬로 표현한 것
- 각 문서에 대한 BoW를 하나의 행렬로 만든 것과 동일

TF-IDF (Term Frequency-Inverse Document Frequency)
- 단어의 빈도와 역 문서 빈도를 사용하여 각 단어들마다 중요한 정도를 가중치로 주는 방법
- tf(d, t) : 특정 문서 d에서의 특정 단어 t의 등장 횟수
- df(t) : 특정 단어 t가 등장한 문서의 수
- idf(d, t) : df(t) 에 반비례하는 수
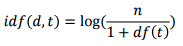
- DTM을 생성
- TF 는 각 문서에서 특정 단어 등장 횟수
tf(문서1, 사과) → 1
df(사과) → 1
idf(d, 사과) → log(4/2) → log2 - tf(문서1, 사과) → 1
tf(문서3, 바나나) → 2
df(사과) → 1
df(바나나) → 2 - '과일이' idf = log(4/1+1)
'바나나' idf = log(4/1+2) - TF-IDF = 각 문서에서 특정 단어 등장 횟수 (tf 값) 에 idf 값을 곱한 값
Tf-idf 실습
from sklearn.feature_extraction.text import TfidfVectorizer
documents = {
'you knew I want your love',
'I like you',
'what should I do',
}
vectorizer = TfidfVectorizer().fit(documents)
print(vectorizer.transform(documents).toarray())
- 검색할때 TF IDF 스코어를 활용을 하기 때문에 TF IDF 같이 나옴
DTM에서 TF-IDF의 차이는?
DTM : Bag of Words 를 행렬로 나타낸 것
→ 모든 문서에서 등장한 단어는 특징이 없다고 의미될 수 있음
→ idf 값을 곱해줌으로써 자주 나오는 단어는 점수를 낮추고, 드물게 나오는 단어는 점수를 높이는 효과
DTM : 순수 단어 카운팅 TF-IDF : 모든 문서에서 등장하는 단어는 가중치를 낮추고, 드물게 나오는 단어는 가중치를 높이는 알고리즘
임베딩
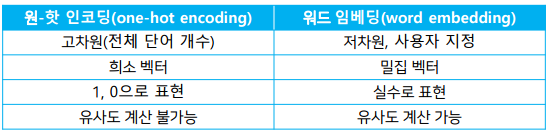
희소표현 (Sparse Representation)
- 원핫인코딩(one-hot encoding 방식) , tf-idf
- 엄청 큰 메트릭스지만 특정부분에 하나씩만 사용
→ 숫자가 나오는것 자체가 희소하기 때문에 희소표현이라고 부름
밀집표현 (Dense Representation)
- word2vec
- 차원을 줄일때 사용자 설정값으로 줄이고, 벡터가 조밀해졌다고 해서 밀집벡터이라고 부름
- 0보다는 거의 모든 케이스에 값이 다 들어있다
워드 임베딩
- 밀집표현으로 벡터를 표현하는 방법
- 임베딩 벡터 - 워드 임베딩 과정을 통해 나온 벡터
- Word2Vec , Glove , FastText
Word2Vec
- 비슷한 위치에서 등장하는 단어들은 비슷한 의미를 가진다라는 가정
- ‘강아지’와 ‘고양이’는 주변에 서로 비슷한 단어가 나올 것
- ‘강아지’와 ‘자연어’는 주변에 전혀 다른 단어가 나올 것
- 중심 단어와 주변 단어로 학습하므로 라벨링이 필요 없음
- 문장이 들어왔을때 tokenizer 한 다음에 해당 token들을 가지고 '강아지'라는 단어가 있을때 앞이나 뒤에 있는 단어들을 보고 학습
- → 비지도학습(unsupervised learning)
- CBOW(Continuous Bag of Words), Skip-gram 방식
CBOW (Continuous Bag of Words)
- 주변에 있는 단어로부터 중심 단어를 예측하는 방법
- 중심 단어를 예측하기 위해서 앞, 뒤로 몇 개의 단어를 볼지에 대한 범위를 윈도우(window)라고 함
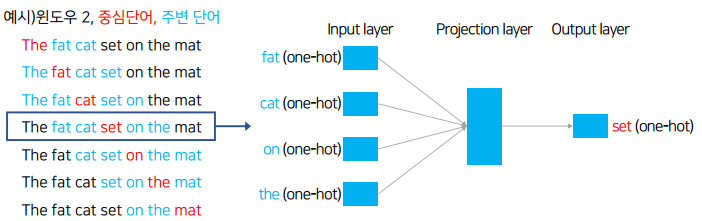
→ Projection layer 모델은 복잡할 수 있음
→ set 이라는 단어를 예측하기 위해서는 fat , cat , on , the 라는 단어들을 가지고 예측을 한다.
→ 윈도우가 3개면 앞에 3단어 , 뒤에 3단어로 학습
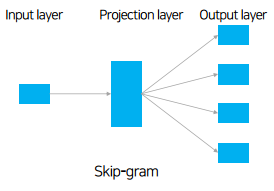
Skip-gram
- CBOW와 반대되는 개념 - 입력과 아웃풋이 반대
- 중심단어에서 주변단어를 예측하는 방식
네거티브 샘플링 (Negative Sampling)
- one-hot encoding으로 모든 단어에 대해서 cross entropy를 계산하고 weight를 조정하려면 단어 개수에 따라서 무거운 작업이 될 수 있음
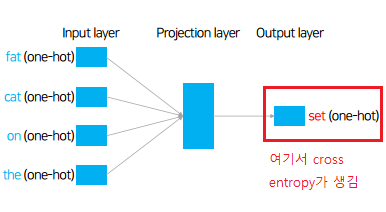
→ 만약 단어가 10만개가 있다면 10만에 대한 cross entropy를 계산을 해야하는데 너무 오래 걸릴 수가 있다. 단어 갯수가 많아질수록 무거워진다.
→ 그래서 sampling 샘플링을 해준다.
- 주변 단어-중심 단어 관계를 가지고 지정한 윈도우 사이즈 내에 존재하면 1, 그렇지 않으면 0으로 이진분류 문제로 변경하여 학습하면 더 빠르게 학습할 수 있음
→ cross entropy는 binary에 대해서만 계산하면 되고 , weight도 두개만 업데이트하면 됨 - 전체 단어가 아니라, 일부에 대해서만 학습하도록 샘플링
Word2Vec 같은 경우 비지도 학습이다 보니 방대한 양의 데이터 학습 가능
→ 데이터가 너무 많기 때문에 네거티브 샘플링처럼 샘플링을 해서 연관이 있는지 학습
코사인 유사도 (Cosine Similarity)
- 두 특성 벡터간의 유사정도를 코사인 값으로 표현한 것
- 코사인 유사도는 -1에서 1까지의 값을 가지며, -1은 서로 완전히 반대, 0은 서로 독립, 1은 서로 같은 경우를 의미
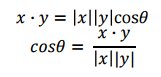
그 외의 유사도 평가 방법 유클리드 거리(Euclidean Distance) , 자카드 유사도(Jaccard Similarity)
Word Analogy
- 유추를 통한 평가로 유추에 대한 데이터가 존재해야 테스트를 할 수 있음
- 명사뿐만이 아니라 형용사, 동명사에서도 똑같이 비슷하게 나오기도 함
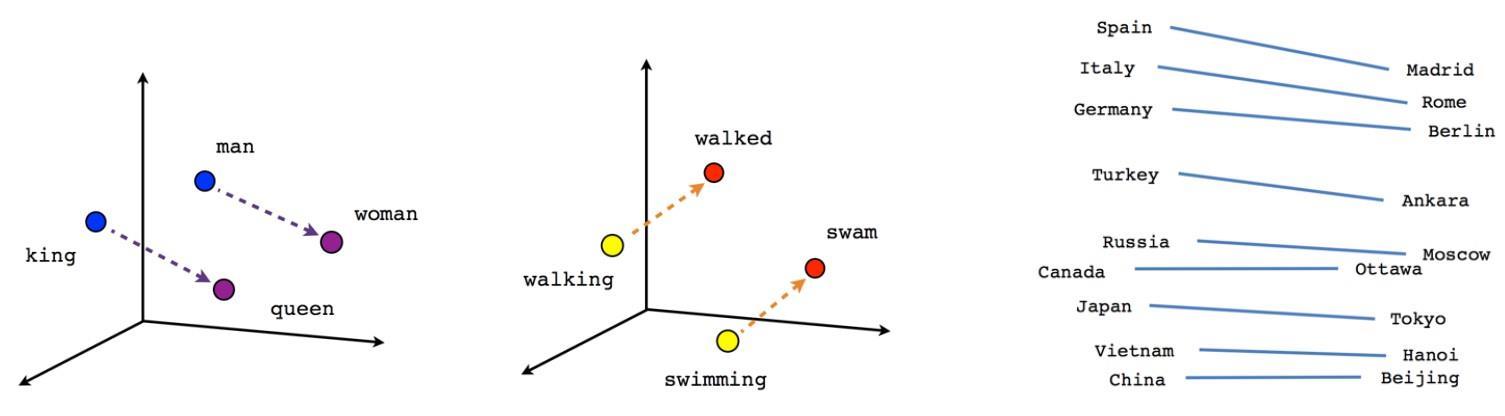
→ man - woman + king = queen
→ 한국 - 서울 = 일본 - 도쿄
반응형
'AI > 자연어처리' 카테고리의 다른 글
| [AI] Embedding + LSTM 분류 예제 (0) | 2020.12.16 |
|---|---|
| [AI] Word2Vec, GloVe, FastText, ELMo 기본 설명 및 실습 (0) | 2020.12.16 |
| [AI] 벡터화 및 One-Hot Encoding 실습 (0) | 2020.11.27 |
| [AI] 데이터 전처리의 이해 및 실습 (2) | 2020.11.27 |
| [AI] 자연어 처리의 이해 (0) | 2020.11.27 |