반응형
벡터화
- 자연어가 기계가 이해할 수 있도록 숫자로 변환해주는 과정
원-핫 인코딩(One-Hot Encoding)
- 단어 집합의 크기를 벡터의 차원으로 하고, 표현하고 싶은 단어의 인덱스에 1의 값을 부여하고, 다른 인덱스에는 0을 부여하는 벡터 표현 방식
- 원-핫 인코딩 과정
- 각 단어에 고유한 인덱스 부여
- 표현하고 싶은 단어의 인덱스에 1, 아닌 단어에는 0 부여
원-핫 인코딩 실습1
from my_tokenizer import tokenize
# 사전 생성
def make_vocab(tokens):
word2index = {}
for voca in tokens:
if voca not in word2index.keys():
word2index[voca] = len(word2index)
return word2index
# 원핫인코딩
def one_hot_encoding(word, word2index):
one_hot_vector = [0] * (len(word2index))
index = word2index[word]
one_hot_vector[index] = 1
return one_hot_vector
if __name__ == '__main__':
document = '안녕하세요. 이번에 같이 교육받게 된 김지선이라고 합니다.'
tokens = tokenize(document, 'lemma')
word2index = make_vocab(tokens)
# print(word2index)
print('dictionary:', word2index)
print(one_hot_encoding('같이', word2index))

원-핫 인코딩 실습2
import nltk
from nltk.tokenize import sent_tokenize
from nltk import WordPunctTokenizer
from nltk.stem import LancasterStemmer
from nltk.stem import WordNetLemmatizer
class Tokenizer:
def __init__(self, tokenize_type): # 클래스로 만들어서 self 가 자동으로 붙음
self.type = tokenize_type
def make_vocab(self, document):
tokens = self.tokenize(document)
word2index = {'<unk>': 0}
for voca in tokens:
if voca not in word2index.keys():
word2index[voca] = len(word2index)
self.vocab = word2index
print('dictionary:', self.vocab)
# types = ['stem', 'lemma', 'pos']
def tokenize(self, document):
words = []
sentences = sent_tokenize(document) # sentence tokenizing
for sentence in sentences:
words.extend(WordPunctTokenizer().tokenize(sentence)) # word tokenizing
if self.type == 'stem':
lancaster_stemmer = LancasterStemmer()
tokenized = [lancaster_stemmer.stem(w) for w in words] # stemming
elif self.type == 'lemma':
lemmatizer = WordNetLemmatizer()
tokenized = [lemmatizer.lemmatize(w).lower() for w in words] # lemmatizing
elif self.type == 'pos':
# tokenized = nltk.pos_tag(words) # pos tagging
tokenized = [token[0] + '/' + token[1] for token in nltk.pos_tag(words)]
else:
raise TypeError
return tokenized
def one_hot_encoding(self, word):
one_hot_vector = [0] * (len(self.vocab))
if word not in self.vocab:
word = "<unk>"
index = self.vocab[word]
one_hot_vector[index] = 1
return one_hot_vector
def get_vector(self, sentence):
# return 2차원 배열
tokens = self.tokenize(sentence)
print('Tokenized:', tokens)
return [self.one_hot_encoding(token) for token in tokens]
if __name__ == '__main__':
document = 'Hi! 안녕하세요.\n 이번에 같이 교육받게 된 김지선\n이라고 합니다.'
tokenizer = Tokenizer('lemma')
tokenizer.make_vocab(document)
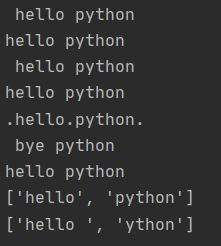
print(tokenizer.get_vector('hi, 같이 김지선'))
반응형
'AI > 자연어처리' 카테고리의 다른 글
| [AI] Embedding + LSTM 분류 예제 (0) | 2020.12.16 |
|---|---|
| [AI] Word2Vec, GloVe, FastText, ELMo 기본 설명 및 실습 (0) | 2020.12.16 |
| [AI] 단어표현방법 (Bag of Words, Word2Vec, One-hot Vector 등) 설명 및 실습 (1) | 2020.12.15 |
| [AI] 데이터 전처리의 이해 및 실습 (2) | 2020.11.27 |
| [AI] 자연어 처리의 이해 (0) | 2020.11.27 |