반응형
단어표현방법(word representation) 및 Word2Vec에 대한 설명 포스팅 참고 ↓
[AI] 단어표현방법 (Bag of Words, Word2Vec, One-hot Vector 등) 설명 및 실습
word2vec 실습
다운로드
https://dumps.wikimedia.org/kowiki/latest/
kowiki-latest-pages-articles.xml.bz2 다운로드 받고 Zip 파일 압축 풀지 않고 바로 붙여 넣기
wikimedia 데이터를 받은 후 바로 사용이 불가능하다. → 데이터 전처리를 위해 아래의 github 주소의 코드를 다운로드 (wikimedia 데이터를 전처리, 추출하기 위한 소스코드)
https://github.com/MouhamadAboShokor/wikiextractor
다운로드 ZIP → 압축 풀고 폴더 복붙

파이참에서 터미널 열기
- day3 폴더로 이동 → cd C:\Python\nlp2\day3
- python -m wikiextractor.WikiExtractor kowiki-latest-pages-articles.xml.bzs 입력
→ parsing 파싱 시작! (시간이 꽤 걸림) - wikiextractor 라이브러리를 Install 한다.
cmd창
- day3의 text 폴더로 이동 → cd C:\Python\nlp2\day3\text
- txt 파일 복사 → copy AA\wiki* wikiAA.txt
- wikiextractor-master 폴더 안에 생성된 wikiAA.txt 파일을 day3 폴더로 이동시킨다.

data_preprocessing.py
- 필요 없는 라인 <doc 으로 시작하거나 </doc>으로 시작하거나 빈문장은 넘어감
with open('wiki_preprocessed.txt','w',encoding='utf-8') as fw:
with open('wikiAA.txt','r',encoding='utf-8') as fr:
for line in fr.readlines():
if line.startswith('<doc') or line.startswith('</doc>') or len(line.strip())==0:
continue
fw.write(line)
print('done')→ 깨끗하게 preprocessing 된 wiki_preprocessed.txt 파일이 생성됨
word2vec.py
from gensim.models import Word2Vec
data = []
with open('wiki_preprocessed.txt', 'r', encoding='utf-8') as fr:
for line in fr.readlines():
words = line.strip().split()
data.append(words)
#print(data)
print('Word2Vex training start')
# data : should 2D list.(list of sentences) size : vector size, min-count : 5번이상나온것만 데이터를 만듬 , workers : 변결처리, sg가 1일때 skip-gram 0이면 CBOW
model = Word2Vec(data, size=100, window=5, min_count=5, workers=4, sg=1)
model.save('word2vec.model')word2vec_test.py
from gensim.models import Word2Vec
model = Word2Vec.load('word2vec.model')
print(model.wv.vocab.keys())
문장 단위로 말고 형태소 분석으로 한번 다시 해보자 ↓
word2vec.py
from konlpy.tag import Okt
from gensim.models import Word2Vec
okt = Okt()
data = []
with open('wiki_preprocessed.txt', 'r', encoding='utf-8') as fr:
for line in fr.readlines():
morphs = okt.pos(line.strip())
data.append([morph[0] for morph in morphs])
print('Word2vec training start')
model = Word2Vec(data, size=100, window=5, min_count=5, workers=4, sg=1) #size: vector size, data: should 2D list.(list of sentences)
model.save('word2vec_morph.model')
print('done')
word2vec_test.py
import numpy as np
from gensim.models import Word2Vec
model = Word2Vec.load('word2vec.model')
# print(model.wv.vocab.keys())
def is_oov(token):
if token not in model.wv.vocab.keys(): # 단어가 있는가? 있으면 False 없으면 True
return True
else:
return False
# # OOV 테스트
print(is_oov('대한민국'))
print(is_oov('서울'))
print(is_oov('일본'))
print(is_oov('도쿄'))
# # 유사도 테스트
print(model.similarity("대한민국", "일본"))
print(model.similarity("서울", "도쿄"))
print(model.similarity("강아지", "고양이"))
print(model.similarity("강아지", "서울"))
# most similar
print(model.most_similar("강아지"))
# analogy test
# 대한민국 + 일본 - 서울
print(model.most_similar(positive=["대한민국", "일본"], negative=["서울"]))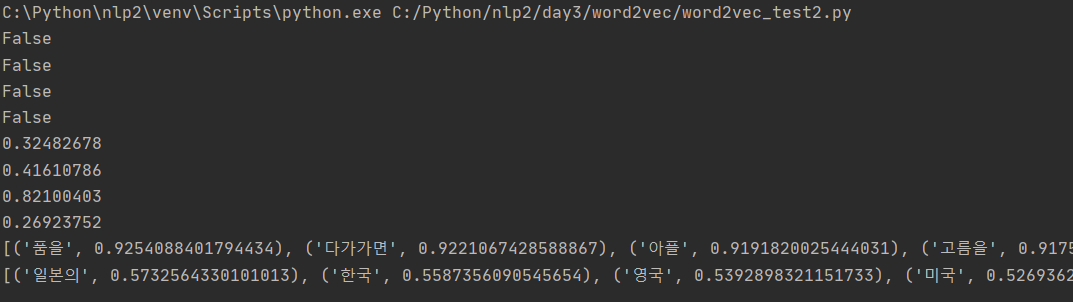
wikidata 같은 경우 많이 활용됨
GloVe (Global Vectors for Word Represintation)
- 카운트 기반과 예측 기반을 모두 사용하는 방법 → Word2Vec은 예측만 사용
- 임베딩 된 중심 단어와 주변 단어 벡터의 내적이 전체 코퍼스에서의 동시 등장 확률이 되도록 만드는 것
https://nlp.stanford.edu/projects/glove/
→ Glove에 대한 자세한 정보, pre-trained 된 모델들도 다운로드할 수 있음
- 영어권에서는 제일 많이 활용되는 Word2Vec 모델 중 하나
- OOV에 문제가 있음
학습을 할 때 동시 등장 행렬을 따로 계산을 해준다
→ 동시 등장 행렬 : 특정 단어가 동시 등장 횟수를 카운트를 하고 특정 단어가 등장했을 때 다른 단어가 등장할 조건부 확률
glove 실습
https://github.com/stanfordnlp/GloVe

glove.6B.zip 파일 다운로드하고 압축을 풀면 txt 파일이 4개가 생성이 되는데 이걸 파이참 glove 폴더 안에 복사 붙여 넣기
파이참에서 glove_python 라이브러리 Install 하기!!
nlp2 > day3 > glove 폴더 > glove_loading.py
- vector = temp[1:]에 50차원의 실수가 들어있는데 str로 읽혔기 때문에 float로 바꿔야 함 → glove[word] = list(map(float, vector))
import numpy as np
def cosine_similarity(A, B):
return np.dot(A, B) / (np.linalg.norm(A) * np.linalg.norm(B))
glove = {}
with open('glove.6B.50d.txt', 'r', encoding='utf-8') as fr:
for line in fr.readlines():
temp = line.strip().split()
word = temp[0]
vector = temp[1:]
glove[word] = list(map(float, vector))
print('glove vector loaded')
# vector = glove['dog']
# print(cosine_similarity(vector, vector))
print(cosine_similarity(glove['dog'], glove['cat']))
glove 벡터를 사용할 때 코사인 유사도를 직접 만들어서 사용하면 됨
Glove는 학습이 되게 잘 돼있어서 성능이 잘 나옴
FastText
- 위에서 Glove모델에서 OOV의 문제를 해결하기 위해 만들 Word 임베딩 모델
- 단어를 n-gram으로 나눠서 학습
- n-gram은 글자 개수로 나눠서 토큰을 만든다.
- n-gram의 범위가 2-5로 설정한 경우 : assumption = {as, ss, su, …, ass, ssu, sum, …, mptio, ption, assumption}
- 학습할 때 없던 단어가 들어왔을 때도 n-gram에 대한 단어는 웬만하면 있어서 커버 칠 수 있음
- 실제 사용 시에는, 입력 단어가 사전에 있을 경우 해당 단어의 벡터를 곧바로 리턴하고 사전에 없는 경우 (OOV, Out-of-Vocabulary) 입력 단어의 n-gram vector를 합산하여 반환
https://research.fb.com/fasttext/ → github 주소도 있음
사람들이 오타를 냈을 때도 각 n-gram의 벡터의 합을 반환하기 때문에 비슷한 단어가 나올 수 있음
fasttext 실습
nlp2 > day3 > fasttext
- gensim에서는 word2vec 로딩을 위한 함수를 제공함
→ 이미 tokenize가 되어 있어야 함
import gensim
from gensim.models.fasttext import FastText
path = '../word2vec/wiki_preprocessed.txt'
# gensim에서는 word2vec 로딩을 위한 함수를 제공함
sentences = gensim.models.word2vec.Text8Corpus(path)
model = FastText(sentences, min_count=5, size=100, window=5)
model.save('fasttext_model')
saved_model = FastText.load('fasttext_model')
word_vector = saved_model['이순신']
print(word_vector)
print(saved_model.similarity('이순신', '이명박'))
print(saved_model.similarity('이순신', '원균'))
print(saved_model.similar_by_word('이순신'))
print(saved_model.similar_by_word('조선'))
saved_model.most_similar(positive=['대한민국', '도쿄'], negative=['서울'])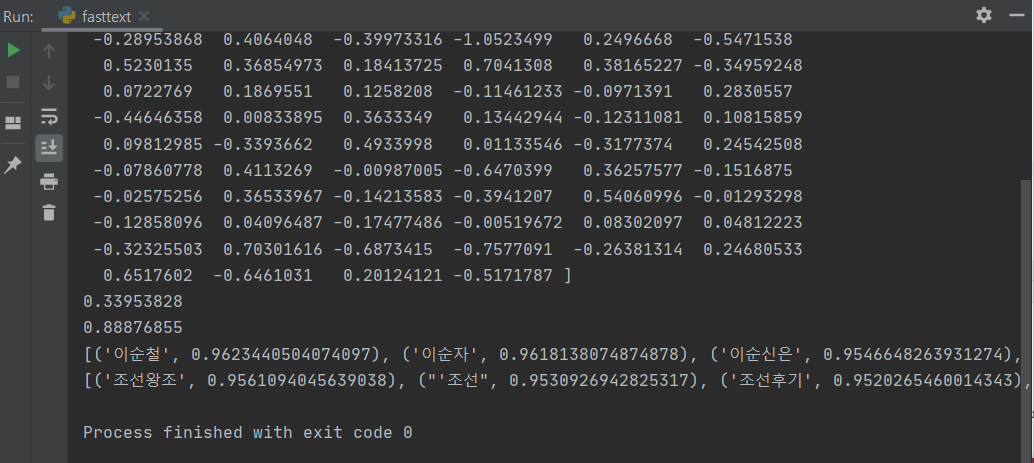
import gensim
from gensim.models.fasttext import FastText
path = '../word2vec/wiki_preprocessed.txt'
# gensim에서는 word2vec 로딩을 위한 함수를 제공함
sentences = gensim.models.word2vec.Text8Corpus(path)
model = FastText(sentences, min_count=5, size=100, window=5)
model.save('fasttext_model')
saved_model = FastText.load('fasttext_model')
word_vector = saved_model['이순신']
print(word_vector)
print(saved_model.similarity('이순신', '이명박'))
print(saved_model.similarity('이순신', '원균'))
print(saved_model.similar_by_word('이순신'))
print(saved_model.similar_by_word('조선'))
saved_model.most_similar(positive=['대한민국', '도쿄'], negative=['서울'])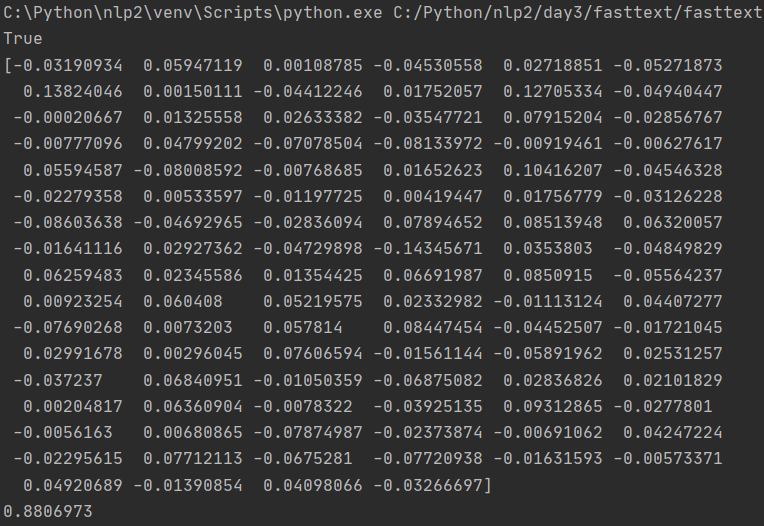
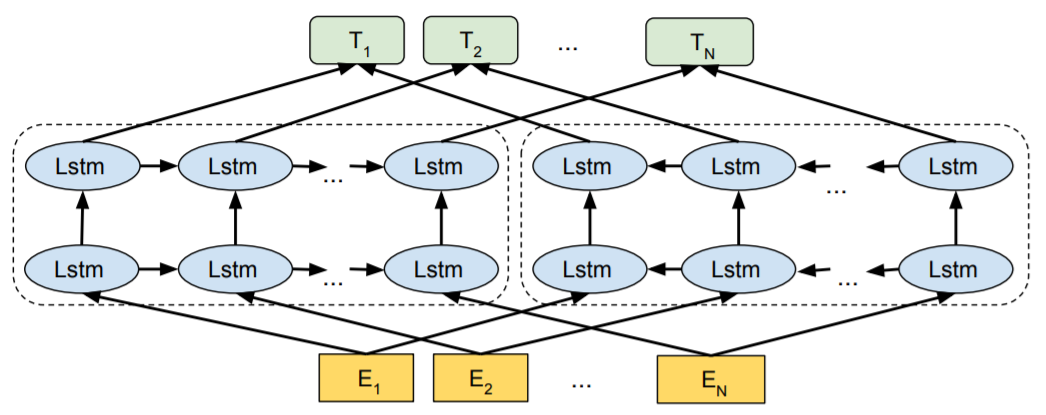
ELMo (Embeddings from Language Model)
- 위의 word2vec 모델들 같은 경우에는 윈도우 사이즈가 있다보니까 window 내에 있는 단어들에 대해서만 학습을 하는데 밖에 있어도 문맥을 반영을 하고 싶고, 글자가 같은 단어도 다른 뜻을 가지는 경우가 있는데 그런 문제를 해결하기 위해 고안한 모델
- Pre-trained 모델의 시작

→ 위의 그림처럼 단어의 뜻이 다른데도 벡터가 하나밖에 없으면 문제이기 때문에 해결하고, 문장의 전체 문맥까지 고려할 수 있는 임베딩 기법
- Elmo는 언어모델인데, lstm을 가지고 순방향 하나 역방향 하나 만들어서 합친것
- 입력이 문장으로 들어가고, 나올때도 문장 기준으로 벡터가 나옴
- 한칸의 한칸의 벡터들이 워드에 대한 벡터이기는 하지만 문맥을 고려해서 벡터를 입력을 받기 때문에 문장을 입력했을 때 성능이 훨씬 잘나옴
반응형
'AI > 자연어처리' 카테고리의 다른 글
| [AI] Annoy (Approximate Nearest Neighbors Oh Yeah) 설명 및 예제 (0) | 2020.12.17 |
|---|---|
| [AI] Embedding + LSTM 분류 예제 (0) | 2020.12.16 |
| [AI] 단어표현방법 (Bag of Words, Word2Vec, One-hot Vector 등) 설명 및 실습 (1) | 2020.12.15 |
| [AI] 벡터화 및 One-Hot Encoding 실습 (0) | 2020.11.27 |
| [AI] 데이터 전처리의 이해 및 실습 (2) | 2020.11.27 |