반응형
CNN (Convolutional Neural Network)
- CNN은 최소한의 전처리(preprocess)를 사용하도록 설계된 다계층 퍼셉트론의 한 종류이다.
- CNN은 하나 또는 여러개의 합성곱 계층과 그 위에 올려진 일반적인 인공 신경망 계층들로 이루어져 있으며, 가중치와 통합 계층(pooling layer)들을 추가로 활용한다.
- DNN에서는 Dense Layer를 사용한다. → Dense Layer는 Wx+b이라서 Linear와 Rogistic 회귀가 합쳐진 느낌
- CNN에서는 Convolution이라는 연산을 활용함
퍼셉트론 관련 포스팅 [AI] 딥러닝의 개요 - 퍼셉트론
DNN 관련 포스팅 [AI] DNN(Deep Neural Network)의 이해 및 실습
합성곱 (Convolution)
- 원래는 필터가 정해져 있고 필터를 거쳐서 나오는 것을 특징으로 활용해서 기존에 머신러닝에서 feature 추출하는 방향으로 사용을 했었는데 딥러닝에서 넘어오면서 Convolution에서 필터 자체도 학습하도록 메커니즘이 생김

- 필터와 실제 이미지를 겹쳐서 각자 곱한 다음에 9개를 다 더해서 값이 나옴
→ W1*1 + W2*1 + W3*1 + W4*0 + W5*1 + W6*1 + W7*0 + W8*0 + W9*1 - 기존에는 필터를 미리 정의를 해놓고 곱해서 특징을 뽑았었는데, 딥러닝에서는 필터도 학습을 함
원래 필터는 0과 1만 있는 게 아니라 여러 숫자가 나올 수 있고, 소수로 되어있음
합성곱 padding
- Convolution을 하면 사이즈가 작아지는 현상이 발생할 수 있다.
→ 맨 외곽에 padding을 넣어주면 필터가 외곽에서 부터 시작을 하게 되는데 그럼 기존과 크기가 똑같아진다. - 이미지 크기를 조절하기 위해 사용한다.
- 이미지 외곽에 어떤 것이 있는지 인식하는 학습 효과도 있음
- padding은 기본적으로 0으로 만든다.
Pooling
- Convolution layer의 출력을 입력으로 받아서 크기를 줄이거나 특정 데이터 강조
- 이미지의 크기가 너무 크다보니 데이터를 그대로 사용하기엔 파라미터가 너무 커지고 연산도 오래걸려서 Pooling 사용으로 크기를 줄여줌
- 학습하는 파라미터가 존재하지 않음! Convolution Layer는 학습 파라미터 존재
- Max Pooling
- 윈도우에서 제일 큰 값을 가지고 오는 Pooling
- Average Pooling
- 윈도우에서 평균 값을 가지고 오는 Pooling
→ 몇 칸 움질일지 정할 수 있고, 윈도우 사이즈(2*2)도 정할 수 있음
→ 조금씩 움직이면 더 세밀하게 되는데 차원이 커지고 연산이 많아져서 성능에는 유리할 수 있지만 속도가 느려짐
Pooling을 사용하면 속도가 빨라지는데 학습 속도도 빨라지고 서비스할 때 추론 속도도 빨라지게 되는데 Pooling을 많이 사용하게 되면 데이터를 없애는 것이기 때문에 데이터 손실이 일어날 수 있어서 성능에 오히려 악영향을 줄 수 있음
손글씨 데이터를 가지고 만든 CNN 구성
- kernel = filter (55 필터 적용) → 학습해야하는 파라미터 수 : 55 = 25개 + b값 = 50개 * 채널갯수
- channels : 필터가 여러개 → padding을 안하면 크기가 줄어든다.
- Convolution Layer → Pooling Layer → Convolution Layer → Pooling Layer → Flattened → (dropout) → softmax Layer
- Flattened → Dense를 하기 위해서 Flatten을 해줘야함, 1열로 세워져야 Dense가 입력으로 들어갈수 있어서 Flatten을 해줌
- Convolution, Pooling Layer ⇒ Feature Extaction (특징 추출)
- Fully-Connected ⇒ Classification (분류)
Convolution Layer가 의미하는게 무엇인가?? 특징을 추출하는 부분
CNN 실습
import tensorflow as tf
# data download
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
- 이미지의 경우, 위의 코드처럼 쓰면 2차원으로 받아오는데 실제로는 3차원이 Convolution Layer에 들어가야해서 데이터를 바꿔줘야함
- 28*28에 대한 60000개의 데이터가 x_train에 들어있어서 원래는 3차원이 들어가있는데 4차원으로 바꿔줘야함
- Convolution을 할 때는 지금은 흑백이라서 채널이 한개짜린데 원래 이미지는 RGB 채널을 가지기때문에 채널이 기본적으로 3개가 있음! 그렇기 때문에 이미지의 input은 3차원이 들어가야하므로 reshape를 해줘야 학습이 됨
→ 2828 의 이미지에 채널 1개를 곱해서 (28*28*1) - 3차원 - reshape : 모양을 변경하는 함수 → 기존과 바뀐 것의 데이터 총 사이즈는 같아야함
x_train = x_train.reshape((60000, 28, 28, 1)) # 60000만개의 학습 데이터
x_test = x_test.reshape((10000, 28, 28, 1))
원래 이미지는 RGB로 되있기 때문에 3차원인데 손글씨는 2차원이기때문에 3차원으로 변경을 해준것이다!!
그런데 Conv2D를 쓰는 이유는?
어쨋든 convolution 자체는 Convolutin 필터 사이즈가 2차원이기때문에!! 2차원으로만 컨볼루션 연산을 하기 때문에 Conv2D 함수를 쓰는거임
- 모델 정의
- Conv2D : convolution 2D 이미지를 사용
→ 32 : 채널갯수 , (5, 5) : 필터 사이즈
→ 처음에는 input_shape를 지정해줘야함 - MaxPooling2D : 2*2 윈도우 사이즈
- 채널갯수, hidden Layer 갯수는 임의로 넣은 값임
- Conv2D : convolution 2D 이미지를 사용
#model define
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Conv2D(32, (5, 5), activation='relu', input_shape=(28,28,1)))
model.add(tf.keras.layers.MaxPooling2D((2, 2)))
model.add(tf.keras.layers.Conv2D(64, (5, 5), activation='relu'))
model.add(tf.keras.layers.MaxPooling2D((2, 2)))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(64, activation='relu'))
model.add(tf.keras.layers.Dense(10, activation='softmax'))model.summary()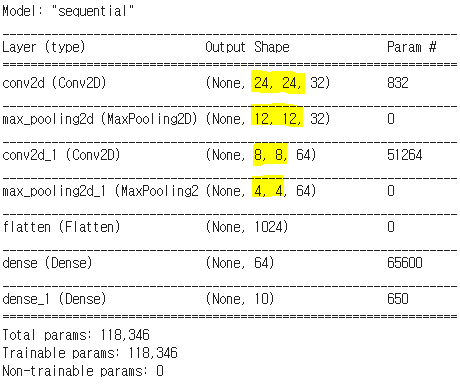
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(x_train, y_train, epochs=10)
model.evaluate(x_test, y_test, verbose=2)
반응형
'AI > 이미지인식' 카테고리의 다른 글
| [AI] Image Classification과 Backbone의 이해 (0) | 2022.06.08 |
|---|