반응형
RNN - 시계열데이터 (자연어처리, 센서데이터, 주식데이터)
순환신경망 (Recurrent Neural Network)
- DNN은 시퀀스에 대한 부분이 처리가 안되어 이를 위해 고안된 모델이 RNN
- 앞에서 계산한 가중치를 가지고 가중치를 계산할 때 참고를 하다보니 시계열데이터가 더 잘됨
- 현재 셀에서 이전 셀의 값을 받아서 현재 셀의 상태를 규정
- 이전 셀이 계산이 되어야만 현재 셀이 계산이 되므로 동작 속도가 느리다.

RNN이라고 이미지를 사용하면 안되는건 없고, 이미지든 자연어든 결국 다 숫자로 이루어져 있기 때문에 결국 다 적용가능한데 좀 더 특화된 부분이 자연어처리나 시계열데이터라는 것 뿐임
→ 자연언어 처리에서도 CNN을 활용을 해서 분류를 하기도 한다.
→ CNN보다 RNN이 더 느린데, 왜냐하면 앞에를 계산해야만 뒤에를 계산을 할 수 있음
- Application에 따라서 다양한 방식으로 활용할 수 있음
- 원래는 다대다처럼 모델은 다 있는데 일대다에서는 한개만 넣고 나머지는 빈값만 넣어준다.
- 이미지 캡셔닝 → 이미지에 대한 캡션을 넣고 예측을 하도록 만듬

RNN의 경우, 입력이 길어질수록 앞의 정보가 뒤로 충분히 전달되지 못하는 문제 발생
→ 장기 의존성 문제(Long-Term Dependencies problem)
문장에서는 제일 처음에 온 단어가 중요한 역할을 할 수도 있음
LSTM(Long Short Term Memory)
- RNN의 문제를 해결하기 위해 고안된 모델
- 제일 초반에 들어온 토큰에 대한 정보도 잘 보관을 하고, 최근에 들어온 토큰의 정보도 잘 보관을 할 수 있도록 고안된 모델
- 불필요한 기억은 지우고 기억해야할 것들을 정한다.
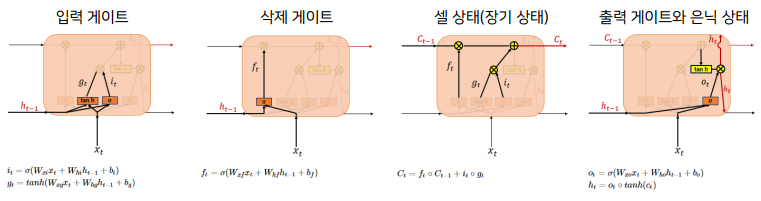
→ 이런식으로 디자인 되어있다.
- 장기 상태는 뭔가 곱해지지 않고 위의 Ct-1에서 보면 그냥 그대로 넘어오는 부분때문에 장기상태가 기억이 된다.
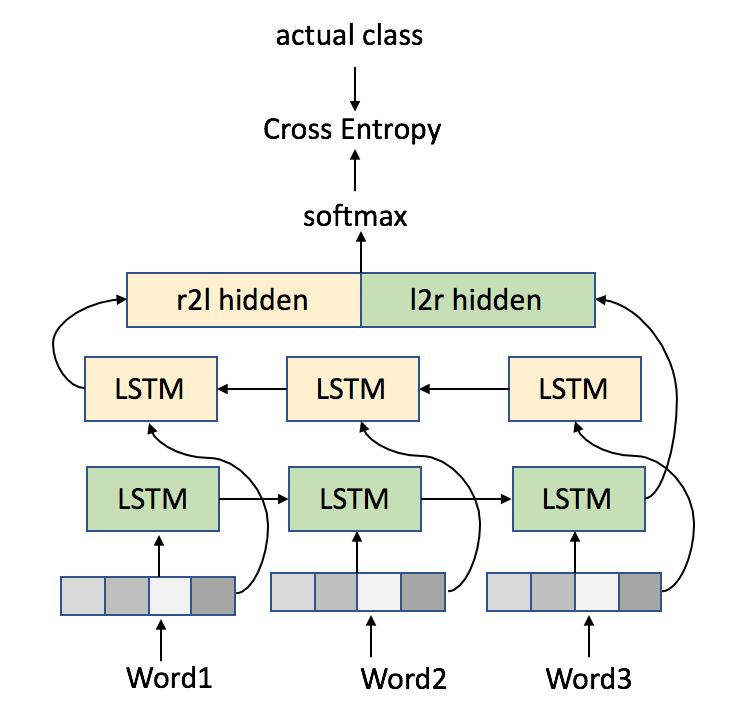
bi-directional LSTM
- LSTM 같은 경우 앞에서부터 뒤로 가면서 왼쪽에서부터 오른쪽으로만 연산을 했는데 그렇게 하는것보다는 언어라는 자체가 뒤에서부터 앞으로 오는것도 의미가 있어서 역방향도 같이 사용을 하는 것이 bi-directional LSTM이다.
- LSTM을 역방향이랑 정방향이랑 같이 쓰고 각각 출력을 붙여서 활용을 하면 병렬처리를 할 수 있어서 속도는 동일한데 성능을 높일 수 있다.
bi-directional은 꼭 LSTM만 해당이 되는 것은 아님. RNN도 bi-directional으로 똑같이 사용 가능하지만 LSTM을 가장 많이 사용하기 때문에 LSTM기준으로 보려고 bi-directional LSTM이라고 함.
GRU(Gated Recurrent Unit)
- LSTM이랑 비슷하지만 학습하는 가중치가 적어서 학습이 조금 더 빠르다.
- 데이터 양이 적을 때는, 매개 변수의 양이 적은 GRU가 조금 더 낫고, 데이터 양이 많을 때는, 매개 변수의 양이 많은 LSTM이 더 낫다고 알려져 있음

RNN기반 분류 실습
- Colab을 이용한 실습
→ 내 컴퓨터에 있는 파일을 Colab에서 불러오게 하려면 특별한 동작을 해줘야 함.- 구글 드라이브랑 연결이 되서 자동 저장됨
- Colab은 내 컴퓨터가 아닌 구글에서 제공하는 서버에 접속해서 동작한다.

⇒ test.tsv , train.tsv 파일을 내 드라이브 Colab 폴더에 data 디렉토리를 만들어서 붙여 놓는다.
from google.colab import drive
drive.mount('/content/drive')
이런 화면이 뜨면 저 URL로 들어가서 계정 선택 후 code 를 복사해서 붙여넣고 엔터키를 누른다.

→ Mounted 가 나오면 Colab이랑 드라이브랑 연결이 됬다는 뜻 (드라이브에 있는 것에 접근 가능함)
fr = open('/content/drive/My Drive/Colab Notebooks/data/news_sample/train.tsv', 'r', encoding='utf-8')
print(fr.readline())→ 파일이 제대로 읽어지는 지 확인하는 코드
→ /content/drive/My Drive 까지가 내 드라이브의 경로

- 데이터를 읽어서 저장하는 코드
- 한 라인에 뉴스기사 하나가 저장이 되게 데이터가 만들어져 있다.
- strip() : 양쪽의 공백제거 → 뉴스기사 하나를 읽으면 \n가 있어서 다음 기사로 넘어가는데 그것을 없애주기 위한 작업
- tsv는 tab으로 나눠서 엑셀처럼 쓰는 함수!! → tab으로 split('\t')을 해서 나눈 후 1번째는 label , 3번째 들어있는 것을 title , 4번째 들어있는 것을 content로 나눠서 가져온다.
- if문 부분
- label_dic 이라는 것을 만든다. → 새로운 label이 들어올때마다 label_dic 을 만든다.
- 코드 아래에 만들어진 label_dic 캡처본 확인
- 실제 train_labels 에 넣을때는 숫자로 들어가게 된다.
- train_text 는 title이랑 content를 넣을 때 그 사이에 개행문자를 넣는다.
- label이 지금은 세개 다 텍스트로 들어가 있는데 전부 숫자로 바꿔주는 작업
label_dic = {}
train_texts, train_labels = [], []
test_texts, test_labels = [], []
# 데이터를 읽어서 저장하는 코드
# 450건
with open('/content/drive/My Drive/Colab Notebooks/data/news_sample/train.tsv', 'r', encoding='utf-8') as fr:
lines = fr.readlines()
for line in lines:
line = line.strip().split('\t')
label = line[1]
title = line[3]
content = line[4]
if label not in label_dic.keys():
label_dic[label] = len(label_dic)
train_texts.append(title + '\n' + content)
train_labels.append(label_dic[label])
# 50건
with open('/content/drive/My Drive/Colab Notebooks/data/news_sample/test.tsv', 'r', encoding='utf-8') as fr:
lines = fr.readlines()
for line in lines:
line = line.strip().split('\t')
label = line[1]
title = line[3]
content = line[4]
test_texts.append(title + '\n' + content)
test_labels.append(label_dic[label])
import nltk
from nltk.tokenize import sent_tokenize
from nltk import WordPunctTokenizer
import numpy as np
import tensorflow as tf
nltk.download('punkt') # wordTokenizer 쓸때 필요한 리소스
- 전처리 과정 Tokenizer
- one_hot_encoding 함수까지는 그저께 만든 코드랑 동일
→ 딥러닝에서는 전체길이가 똑같아야 되기 때문에 행렬 연산은 사이즈가 똑같아야 연산이 가능
→ 256보다 큰 경우에는 0 벡터를 붙여주고 256 까지만 벡터를 반환- get_vector 함수에서 while문은 전체 길이를 256까지만 맞춰주는 코드
class Tokenizer:
def make_vocab(self, documents):
word2index = {'<unk>':0}
for document in documents:
tokens = self.tokenize(document)
for voca in tokens:
if voca not in word2index.keys():
word2index[voca] = len(word2index)
self.vocab = word2index
def tokenize(self, document):
words = []
sentences = sent_tokenize(document)
for sentence in sentences:
words.extend(WordPunctTokenizer().tokenize(sentence))
return words
def one_hot_encoding(self, word):
one_hot_vector = [0] * len(self.vocab)
if word not in self.vocab:
word = '<unk>'
index = self.vocab[word]
one_hot_vector[index] = 1
return one_hot_vector
def get_vector(self, sentence):
tokens = self.tokenize(sentence)
vector = [self.one_hot_encoding(token) for token in tokens]
while len(vector) < 256:
vector.append([0] * len(self.vocab))
return vector[:256]tokenizer = Tokenizer()
tokenizer.make_vocab(train_texts)→ 전체 학습 데이터로 vocab을 생성해준다.

- get_vector를 하면 안에서 tokenize를 한 다음에 알아서 256개까지의 벡터를 반환해준다.

- train_text 를 숫자로 바꾸는 코드
→ np.array 로 감싸주는 이유는 그래야 tensorflow 에서 활용을 할 수 있음- get_vector를 쓰면 된다.
x_train = np.array([tokenizer.get_vector(text) for text in train_texts])
x_test = np.array([tokenizer.get_vector(text) for text in test_texts])
# train_labels은 숫자로는 되어있는데 numpy로는 안되있어서 array로 감싸준다.
y_train = np.array(train_labels)
y_test = np.array(test_labels)
print(x_train.shape, x_test.shape)
→ 256개 까지만 사용하기 때문에 256
→ 340은 원핫벡터의 크기, 원핫벡터가 vocab의 사이즈만큼 생성
→ 원핫인코딩은 vocab 사이즈만큼 벡터에서 아닌것만 1로 표시되기 때문에 이런식으로 결과가 나온다.
- 모델 생성
model = tf.keras.models.Sequential()
# 입력에 대한 사이즈 생성 - 입력 layer라서 학습 파라미터는 없음
model.add(tf.keras.layers.Input(shape=(x_train.shape[1], x_train.shape[2])))
# LSTM을 Bidirectional로 감싸줘야함
# model.add(tf.keras.layers.LSTM(128)) -> 이렇게 써도된다.
# 자동으로 LSTM이 다대일로 해서 제일 마지막 결과만 여기 layer에서 출력을 해준다.
model.add(tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(128)))
# 위에서 출력된 결과를 relu로 분류하는 네트워크를 붙여준다.
model.add(tf.keras.layers.Dense(64, activation = 'relu'))
# label이 세개니까 3을 넣어서 softmax layer를 추가
model.add(tf.keras.layers.Dense(3, activation = 'softmax'))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(x_train, y_train, epochs=20)→ compile 해준 후 , fit 함수로 학습

- 학습을 하면 evaluate도 할 수 있다.
model.evaluate(x_test, y_test, verbose=2)
모델을 만드는 부분은 조금 다르지만 cnn 이미지분류를 할때랑 똑같이 compile해주고 , 학습하는 방법(fit)도 똑같다.
이전 포스팅 참고 - 2020/12/15 - [Ai] - [AI] CNN(Convolutional Neural Network)의 이해 및 실습
형태소 분석기 사용
- konlpy 라이브러리 다운
!pip install konlpy
from konlpy.tag import Kkma
kkma = Kkma()
print(train_texts[0])
print(kkma.pos(train_texts[0]))
https://konlpy.org/en/latest/
→ 가장 간단한 형태소 분석기 참고
Seq2seq model
- 번역기에서 대표적으로 사용되는 모델
- 앞에는 LSTM을 쓰는데 다 0으로 쓴다.
→ 여기에 뭐가 나오든 무시하고 버림. 처음의 state가 넘어가고 넘어가다가 state를 새로운 LSTM에 넣는데 여기에서는 <sos> : start of sentence 를 넣었을때 나오는 단어를 그다음부터 입력을 함 - I am a student 를 넣었을 때 스페인어로 번역되서 나오는 모델

- 인코더 셀은 모든 단어를 입력받은 뒤에, 마지막 시점의 은닉 상태를 디코더 셀로 넘겨주며, 이 벡터를 context vector라고 한다.
- 디코더는 초기 입력으로 문장의 시작을 의미하는 심볼이 들어가고, 다음에 등장할 확률이 높은 단어를 예측
반응형
'AI' 카테고리의 다른 글
| [AI] DNN(Deep Neural Network)이란? - 개념 및 실습 (0) | 2020.12.15 |
|---|---|
| [AI] 딥러닝 개요 - 순전파, 역전파 그리고 활성화 함수 (0) | 2020.12.15 |
| [AI] 딥러닝의 개요 - 퍼셉트론 (2) | 2020.11.27 |
| [AI] SVM 과 k-means clustering 이론 및 실습 (0) | 2020.11.27 |
| [AI] 회귀(Regression) 실습 - 선형회귀 및 로지스틱 회귀 (0) | 2020.11.27 |