반응형
BPE (Byte Pair Encoding)
-
BERT 기반 모델들도 다 BPE를 사용을 하기 때문에 알아둬야 함
-
Word embedding
→ 단어 수가 많고, Out-of Vocabulary 문제가 빈번하게 발생함 (한국어로 word2vec을 했을 때 엄청 단어가 많이 나옴)
-
의미 있는 단위로 단어를 자르면 OOV를 피하고 단어 수를 줄일 수 있음
-
의미 있는 단위 판단 기준
- 의미 있는 패턴(subword)은 자주 등장할 것,
- 많이 나오는 패턴은 독립적인 의미를 가지는 subword일 것
→ 결국 word를 서브 워드로 잘라준다.
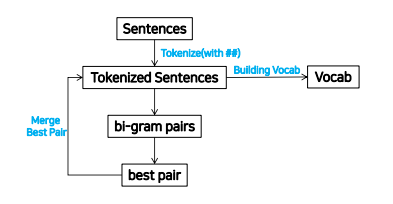
Tokenize
- Vocab을 만들기 위한 문서의 전처리 과정
- 기준이 되는 문서를 character 단위로 분리
Merge Best Pair
- Character 단위로 분리했을 때, 문서에서 가장 많이 등장하는 bi-gram pair를 찾아서 merge
- Iteration을 정해놓고 주어진 횟수만큼 반복해서 수행
Building Vocab
- 정의된 iteration을 모두 수행 후 vocab을 생성
예제
참고 사이트 - https://wikidocs.net/22592
sentence : aaabdaaabac
→ vacab : (a, b, c, d) - 초기에는 character 단위로 잘라줌
→ tokenize를 단위로 잘라줌 : (a a a b d a a a b a c)
→ 2글자 단위로 pair를 만든다 : (aa, aa, ab, bd, da, aa, aa, ab, ba, ac)
→ 제일 많이 등장한 token : aa(4번)
→ Iteration이 한번 끝나면서 vocab에 aa가 추가됨 : (a, b, c, d, aa)
→ 추가된 vocab으로 다시 tokenizing : (aa a b d aa a b a c)
→ 2번의 Iteration을 돌면 : (aa ab d aa ab a c)
→ 3번의 Iteration을 돌면 : (aaab d aaab a c) → vocab은 (a, b, c, d, aa, ab, aaab)
BPE 실습
import _collections
import re
dictionary = {'l o w <end>':5, 'l o w e r <end>':2, 'n e w e s t <end>':6, 'w i d e s t <end>':3}
def get_pair(dictionary):
pairs = _collections.defaultdict(int)
for word, freq in dictionary.items():
symbols = word.split()
for i in range(len(symbols)-1):
pairs[symbols[i], symbols[i+1]] += freq
print('현재 pair:', dict(pairs))
return pairs
def merge_dictionary(pair, v_in):
v_out = {}
bigram = re.escape(' '.join(pair)) # e,s ->'e s' 공백을 확실히 넣어줌
# 앞뒤가 공백인 것을 찾는다 -> 공백제거하고 텍스트찾기
p = re.compile(r'(?<!\S)' + bigram + r'(?!\S)')
for word in v_in:
w_out = p.sub(''.join(pair), word)
v_out[w_out] = v_in[word]
return v_out
epochs = 10
for i in range(epochs):
pairs = get_pair(dictionary)
best = max(pairs, key=pairs.get)
print('best pair:', best[0] + best[1])
new_dictionary = merge_dictionary(best, dictionary)
print('new_dictionary:', new_dictionary)
BERT 모델의 vocab
- [PAD] → tokenizing 할 때 모자라는 파?? 에 대해서 padding을 해주는데 padding에 대한 TOKEN
- [unused0]
- 안쓰는것, 나중에 BERT 모델 바꾸고 싶을 때 단어를 추가하고 싶을 때 이걸 바꿔서 단어를 넣으면 그 단어가 tokenizing이 됨
- 처음에 BERT 모델 학습 할때는 unused는 사용을 안 하고 학습함
- 캐릭터 단위의 문자가 존재함, 특수문자, 일본어도 있음
- 어절 첫번째에 오는 것과 중간에 오는 것을 구별하기 위해 ## 을 이용함
- ex) lovely → love, ly → love, ##ly로 표현함 (나중에 쉽게 갖다 붙일 수 있게 만듬)
- 단어가 분리되지 않고 통째로 나오는 단어들은 사람들이 정말 많이 쓰는 것들임
Vocab을 직접 만드는데 얼마나 잘 만들었는가에 따라서도 BERT 성능이 조금씩 바뀜
반응형
'AI > 자연어처리' 카테고리의 다른 글
| [AI] 최신 기술 이해 및 실습 (Transformers, Self Attention, GPT, BERT 등) (0) | 2020.12.18 |
|---|---|
| [AI] StanfordNLP, Khaiii (Kakao Hangul Analyzer III) 설명 및 예제 (0) | 2020.12.18 |
| [AI] 어텐션 메커니즘(Attention Mechanism)이란? - 개념 및 예제 (0) | 2020.12.17 |
| [AI] Annoy (Approximate Nearest Neighbors Oh Yeah) 설명 및 예제 (0) | 2020.12.17 |
| [AI] Embedding + LSTM 분류 예제 (0) | 2020.12.16 |