반응형
머신러닝 프로세스

과적합(Overfitting)
- 훈련 데이터를 과하게 학습한 상태
- 훈련 데이터에서의 정확도는 매우 높지만, 실제 서비스에서의 데이터에 대해서는 정확도가 좋지 않은 현상
과소적합(Underfitting)
- 테스트 데이터의 성능이 올라갈 여지가 있음에도 훈련을 덜 한 상태
- 대표적으로 Word2Vec
지도학습(Supervised Learning)
- 데이터에 레이블이 있는 경우 → 데이터와 정답을 함께 넣어서 학습
- 대표적으로 분류 문제가 있음
비지도학습(Unsupervised Learning)
- 레이블 없이 주어진 데이터 안에서 학습
- Word2Vec ⇒ 주변 단어는 서로 연관이 있을 것이다 라고 가정해서 주변 단어를 보고 학습
BERT 같은 최신 대규모 언어 모델들도 비지도 학습을 이용해서 1차적으로 모델을 학습하고 그 모델을 다른 Task에 적용하기 위해서 변경을 해줄 때 적은 데이터로 지도학습을 해준다.
강화학습(Reinforcement Learning)
- 행동(Action)에 대한 보상(rewards) 기반으로 학습
- 알파고 , 게임
회귀(Regression)
- 원래 상태로 돌아가는 것
- 회귀분석
- 주어진 자료들이 특정한 경향성을 띄고 있다는 가정을 활용
- 단순 회귀 분석(Simple Regression Analysis)
- 하나의 종속변수에 대해 독립변수가 하나인 경우
- 다중 회귀 분석(Multiple Regression Analysis)
- 하나의 종속변수에 대해 독립변수가 둘 이상인 경우
종속변수 : 입력값이나 원인
독립변수 : 결과물이나 효과
반응형
선형회귀
단순 선형 회귀 분석(Simple Linear Regression Analysis)
- 데이터가 선형 경향을 띈다고 가정
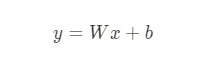
x : 독립변수 , W : 가중치(weight) , b : 편향(bias)
- 가설에 대해서 적절한 W 와 b 를 찾아주는 문제
- 위의 식을 두고 W와 b를 찾아가는 과정
y = 실제값 , H = 가설값
비용함수(cost function or Loss function)
- 딥러닝에서도 똑같이 적용되서 잘 이해하고 넘어가자!! - 인공지능 전반적인 부분에 대해서도 이해가 잘 될것이다.
- 가설과 실제 데이터를 넣었을 때의 값의 차이
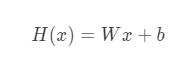
W = 2 , b = 2 로 가정,,
x = 1 대입하면 H(x) = 4 , y = 2 (차이 : 2)
x = 2 대입하면 H(x) = 6 , y = 3 (차이 : 3)
- 학습은 차이를 줄이는 방향으로 W와 b를 조정
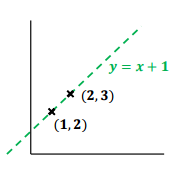
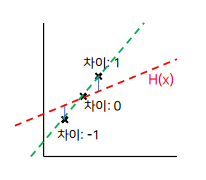
가설과 실제 데이터의 차이 → H(x)-y 를 하면 0이 될 수 있는데 최적화된 값이라고 착각할 수 있음
해결하는 방법은?? 절대값 , 제곱
(H(x)-y)^2 제곱을 취하면, 차이가 큰 경우에 대해서 가중치가 높아지는 효과
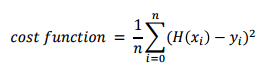
- cost function : 차이를 제곱한 것들의 평균 → 평균 제곱 오차 (Mean Squared Error)
- 단순 선형 회귀 분석에서는 MSE가 많이 활용됨
- MAE , MSLE , MAPE , Cross-entropy 등 다양한 loss function이 존재하므로, 상황에 맞는 loss function 을 정의하는 것도 중요
- 여기서 Cross-entropy는 조금 다른데 분류할 때 많이 쓰인다.
옵티마이저(Optimizer)
- 비용 함수를 최소화하는 W와 b를 찾기 위한 최적화 작업을 학습이라고 부름
- 학습하는 과정은 W와 b를 조정을 해가면서 최적의 값을 찾는 것
- 학습하는 함수를 옵티마이저라고 부른다.
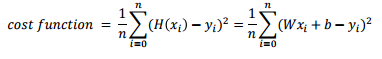
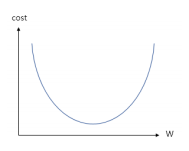
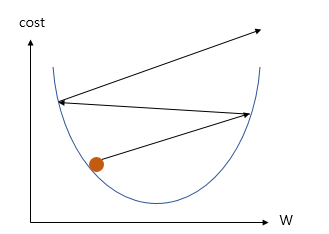
경사 하강법 (Gradient Descent)
- 옵티마이저의 한 종류
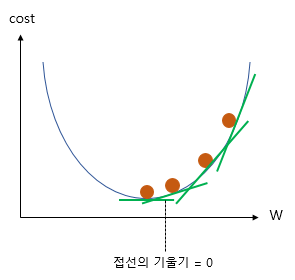
- 임의의 W값을 정한 뒤에, cost 가 최소가 되도록 W를 조금씩 수정하는 방법
- 미분을 통한 접선에서의 기울기를 활용
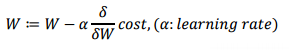
- 기울기를 조금씩 옮길때 learning rate를 곱한 만큼만 옮겨준다.
학습률 (Learning Rate)
- W의 값을 변경할 때, 얼마나 크게 변경할지를 결정
- 너무 크게 정하면 발산, 너무 작게 정하면 학습 속도가 느려짐
반응형
'AI' 카테고리의 다른 글
| [AI] DNN(Deep Neural Network)이란? - 개념 및 실습 (0) | 2020.12.15 |
|---|---|
| [AI] 딥러닝 개요 - 순전파, 역전파 그리고 활성화 함수 (0) | 2020.12.15 |
| [AI] 딥러닝의 개요 - 퍼셉트론 (2) | 2020.11.27 |
| [AI] SVM 과 k-means clustering 이론 및 실습 (0) | 2020.11.27 |
| [AI] 회귀(Regression) 실습 - 선형회귀 및 로지스틱 회귀 (0) | 2020.11.27 |