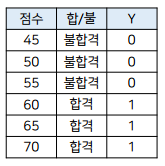
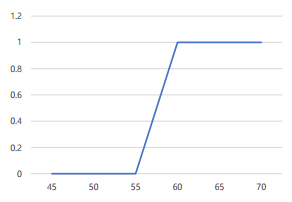
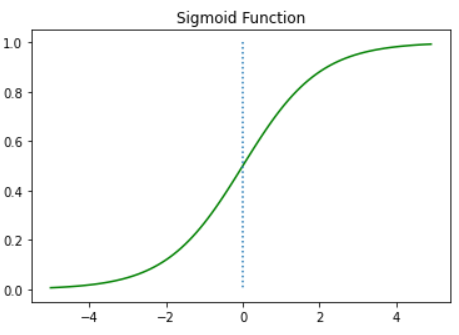
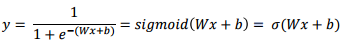설명문 처리
워크시트의 명령을 전달하여 실행 : [CTRL]+[ENTER] 또는 [F5]
[CTRL]+[ENTER] : 커서 위치의 SQL 명령을 전달하여 실행
[F5] : 워크시트의 모든 SQL 명령을 전달하여 실행
범위를 지정하여 [CTRL]+[ENTER] 또는 [F5]를 입력할 경우 범위의 명령만 전달하여 실행 가능
SQL 명령은 대소문자를 구분하지 않으며 하나의 SQL 명령을 구분하기 위해 ;(세미콜론) 사용
테이블(TABLE)
- 데이타베이스에서 정보를 저장하기 위한 기본 객체
- 현재 접속 사용자의 스키마에 존재하는 테이블 목록 확인
SELECT TABLE_NAME FROM TABS;
SELECT * FROM TAB;
테이블의 구조 확인
- 테이블 속성 정보(컬럼명과 자료형)
- 형식) DESC 테이블명
EMP 테이블 : 사원정보를 저장하기 위한 테이블
DEPT 테이블 : 부서정보를 저장하기 위한 테이블
DESC EMP;
DESC DEPT;
DQL(DATA QUERY LANGUAGE)
- 데이타 질의어
- SELECT : 하나 이상의 테이블에서 행을 검색하기 위한 명령
- 형식) SELECT 검색대상,검색대상,... FROM 테이블명, 테이블명,...
- 검색대상 : * (모든 컬럼) - 다른 검색대상과 동시 사용 불가, 컬럼명, 연산식, 함수 등
SELECT * FROM EMP;
SELECT EMPNO, ENAME, SAL, DEPTNO FROM EMP;
COLUMN ALIAS : 검색대상에 별칭(임시 컬럼명)을 부여하는 기능
- 형식) SELECT 검색대상 [AS] 별칭, 검색대상 [AS] 별칭 FROM 테이블명,...
- 검색대상을 명확하게 표현하기 위해 별칭 사용
- AS 생략 가능
SELECT EMPNO AS NO, ENAME AS NAME, DEPTNO AS DNO FROM EMP;
SELECT EMPNO 사원번호, ENAME 사원이름, DEPTNO 부서코드 FROM EMP;
컬럼 별칭으로 공백 또는 특수문자를 사용하고자 할 경우 " " 기호를 사용하여 표현
SELECT EMPNO "사원 번호", ENAME 사원이름, SAL*12 연봉 FROM EMP;
식별자(테이블명, 컬럼명, 컬럼 별칭 등)는 단어와 단어를 _로 구분하여 표현
SELECT EMPNO, ENAME, SAL*12 ANNUAL_SALARY FROM EMP;
|| : 결합 연산자
- 검색대상의 결과값 결합
- 문자형 상수는 ' ' 기호를 이용하여 표현
SELECT ENAME || JOB FROM EMP;
SELECT ENAME || '님의 업무는' ||JOB|| '입니다.' FROM EMP;
EMP 테이블에 저장된 모든 사원의 업무 검색 (중복된 컬럼값 검색)
SELECT JOB FROM EMP;
DISTINCT : 검색대상의 중복값을 제외하고 유일한 하나의 결과값만 검색하는 기능 제공
형식) SELECT [DISTINCT] 검색대상[, 검색대상, ...] FROM 테이블명,...
SELECT DISTINCT JOB FROM EMP;
DISTINCT 키워드에 검색대상을 여러 개 나열 가능
SELECT DISTINCT JOB, DEPTNO FROM EMP;
WHERE : 조건식을 사용하여 조건이 참인 행을 검색하는 기능 제공
형식) SELECT 검색대상,... FROM 테이블명,... WHERE 조건식
EMP 테이블에서 사원번호가 7698인 사원의 사원번호, 사원이름, 업무, 급여 검색
단일행을 검색하고자 할 경우 조건식에 PK 제약조건이 부여된 컬럼을 이용하여 검색
SELECT EMPNO, ENAME, JOB, SAL FROM EMP WHERE EMPNO=7698;
EMP 테이블에서 사원이름이 KING인 사원의 사원번호, 사원이름, 업무, 급여 검색
문자형 상수는 ' ' 기호를 이용하여 표현
문자형 상수는 대소문자를 구분하여 비교
SELECT EMPNO, ENAME, JOB, SAL FROM EMP WHERE ENAME='KING';
EMP 테이블에서 입사일이 1981년 6월 9일인 사원의 사원번호, 사원이름, 업무, 급여, 입사일 검색
날짜형 상수는 ' ' 기호에 RR/MM/DD 형식의 패턴으로 표현 - 검색결과는 RR/MM/DD 표현
SELECT EMPNO, ENAME, JOB, SAL, HIREDATE FROM EMP WHERE HIREDATE='81/06/09';
EMP 테이블에서 업무가 SALESMAN이 아닌 사원의 사원번호, 사원이름, 업무, 급여 검색
SELECT EMPNO, ENAME, JOB, SAL FROM EMP WHERE JOB != 'SALESMAN';
SELECT EMPNO, ENAME, JOB, SAL FROM EMP WHERE JOB <> 'SALESMAN';
EMP 테이블에서 사원이름이 A, B, C로 시작되는 사원의 사원번호, 사원이름, 업무, 급여 검색
SELECT EMPNO, ENAME, JOB, SAL FROM EMP WHERE ENAME < 'D';
이중 검색 - WHERE 조건 AND 조건
EMP 테이블에서 업무가 SALESMAN인 사원 중 급여가 1500 이상인 사원의 모든 정보 검색
SELECT * FROM EMP WHERE JOB = 'SALESMAN' AND SAL >= 1500;WHERE 조건 OR 조건
EMP 테이블에서 부서번호가 10이거나 업무가 MANAGER인 사원의 사원번호, 사원이름, 업무, 급여, 부서번호 검색
SELECT EMPNO, ENAME, JOB, SAL, DEPTNO FROM EMP WHERE DEPTNO=10 OR JOB='MANAGER';
범위연산자를 이용하여 컬럼값이 작은값부터 큰값 범위에 포함될 경우의 조건식 구현
형식) 컬럼명 BETWEEN 작은값 AND 큰값
SELECT * FROM EMP WHERE SAL BETWEEN 1500 AND 3000;
선택연산자를 이용하여 컬럼값이 여러 개중 하나인 경우의 조건식 구현
형식) 컬럼명 IN(값,값,...)
SELECT * FROM EMP WHERE JOB IN('ANALYST' , 'SALESMAN');
EMP 테이블에서 사원이름이 A로 시작되는 사원의 모든 정보 검색
SELECT * FROM EMP WHERE ENAME>='A' AND ENAME<'B';
SELECT * FROM EMP WHERE (ENAME BETWEEN 'A' AND 'B') AND ENAME<>'B';
검색패턴기호 : 부정확한 값을 검색하기 위해 제공하는 기호
- %(전체) 또는 _(문자)
- 값이 비교하기 위해 = 연산자를 사용할 경우 % 또는 _를 문자로 인식하여 비교
SELECT * FROM EMP WHERE ENAME = 'A%';
패턴연산자를 이용하여 검색패턴기호로 조건식 구현
형식) 컬럼명 LIKE '값 또는 검색패턴기호'
SELECT * FROM EMP WHERE ENAME LIKE 'A%';
EMP 테이블에서 이름에 A가 포함된 사원의 모든 정보 검색
SELECT * FROM EMP WHERE ENAME LIKE '%A%';
EMP 테이블에서 이름 두번째 문자가 L인 사원의 모든 정보 검색
SELECT * FROM EMP WHERE ENAME LIKE '_L%';
※ 주의 - LIKE 연산자는 % 또는 _를 검색패턴기호로 인식하여 검색
ESCAPE 키워드를 이용하여 ESCAPE 문자를 표현하기 위한 기호 설정
% 또는 _를 검색패턴기호가 아닌 ESCAPE 문자로 인식되도록 설정
SELECT * FROM EMP WHERE ENAME LIKE '%\_%' ESCAPE '\';
컬럼값 대신 NULL로 표현된 경우 존재하는 값이 아니므로 연산식 미실행
IS 연산자를 이용하여 NULL 비교
형식) 컬럼명 IS NULL 또는 컬럼명 IS NOT NULL
SELECT * FROM EMP WHERE COMM IS NULL;
ORDER BY
- 컬럼값을 비교하여 행이 정렬되도록 검색하는 기능 제공
- 형식) SELECT 검색대상, ... FROM 테이블명, ... [WHERE 조건식] ORDER BY {컬럼명 | 연산식 | 별칭 | INDEX} {ASC | DESC}, {컬럼명 | 연산식 | 별칭 | INDEX} {ASC | DESC}, ...
- ASC : 오름차순 정렬, DESC : 내림차순 정렬
- 첫번째 정렬값이 동일한 경우 두번째 값으로 정렬
- ASC는 생략 가능 (기본값)
SELECT EMPNO,ENAME,JOB,SAL,DEPTNO FROM EMP ORDER BY SAL DESC;
검색대상에는 자동으로 첨자(COLUMN INDEX)가 부여
오라클에서는 첨자가 1부터 1씩 증가되는 값으로 표현
SELECT EMPNO, ENAME, SAL*12 ANNUAL FROM EMP ORDER BY 3 DESC;
EMP 테이블에서 모든 사원의 사원번호, 사원이름, 업무, 급여, 부서번호를 부서번호로 오름차순 정렬하고 같은 부서번호인 경우 급여로 내림차순 정렬하여 검색
SELECT EMPNO, ENAME, JOB, SAL, DEPTNO FROM EMP ORDER BY DEPTNO, SAL DESC;
'DB > Oracle' 카테고리의 다른 글
| [Oracle] 오라클 다운로드 후 작업 (0) | 2022.06.08 |
|---|---|
| [Oracle] JOIN과 서브쿼리 (0) | 2020.12.03 |
| [Oracle] Oracle 함수 (0) | 2020.12.02 |