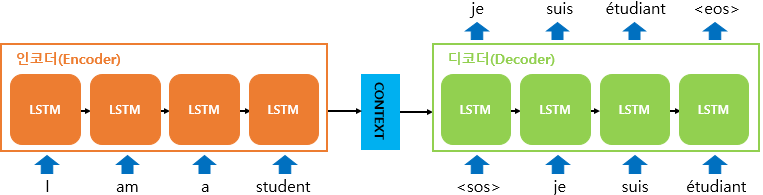
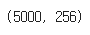전체 문장에 대한 정보를 한꺼번에 벡터 하나로 만들어서 넘겨주니까 token에서의 정보는 하나도 안 남아있고, 전체 문장에 대한 Context만 넘어감
Attention은 Seq2seq model을 보완하고자 만든 것
Attention
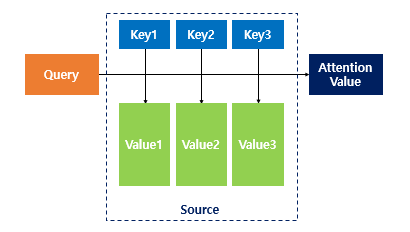
쿼리에 대해서 모든 키와의 유사도를 각각 구하고, 유사도를 키와 맵핑되어 있는 각각의 value에 반영
Query : t 시점의 디코더 셀에서의 은닉 상태
Keys : 모든 시점의 인코더 셀의 은닉 상태
Values : 모든 시점의 인코더 셀의 은닉 상태
→ Attention Value는 Query랑 Key가 들어가서 Value가 곱해져서 다 합쳐진 거임 (먼 소리야ㅎㅎ,,)
Dot-product Attention
매 순간마다 앞에 있던 것을 다 같이 보겠다는 것
기본적으로 곱하기임
→ softmax Layer에서 더 연관이 있는 단어에 weight를 더 많이 줘서 weight들을 전부 더해서 다음에 나올 단어를 예측한다.
그 외의 Attention 종류들
Attention 실습
전에 만들었던 glove_lstm_classification.ipynb 에 attention을 추가해서 만듬
다른 거는 똑같고, model 쪽에 attention 추가
from collections import Counter
import urllib.request
import pandas as pd
import numpy as np
import tensorflow as tf
import nltk
from nltk.tokenize import sent_tokenize
from nltk import WordPunctTokenizer
nltk.download('punkt')
from google.colab import drive
drive.mount('/content/drive')
# spam classification data loading
urllib.request.urlretrieve("https://raw.githubusercontent.com/mohitgupta-omg/Kaggle-SMS-Spam-Collection-Dataset-/master/spam.csv", filename="spam.csv")
data = pd.read_csv('spam.csv', encoding='latin-1')
data[:5]
# glove vector model initialize
glove = {}
with open('/content/drive/My Drive/Colab Notebooks/data/news_sample/glove.6B.50d.txt', 'r', encoding='utf-8') as fr:
for line in fr.readlines():
temp = line.strip().split()
word = temp[0]
vector = temp[1:]
glove[word] = list(map(float, vector))
def tokenize(document):
words = []
sentences = sent_tokenize(document) # sentence tokenizing
for sentence in sentences:
words.extend(WordPunctTokenizer().tokenize(sentence)) # word tokenizing
return [word.lower() for word in words] # case normalization
def get_vector(sentence):
tokens = tokenize(sentence)
vector = [glove[token] if token in glove.keys() else [0]*50 for token in tokens]
while len(vector) < 256:
vector.append([0] * 50)
return vector[:256]
x = [get_vector(text) for text in texts]
x_train, x_test = np.array(x[:5000]), np.array(x[5000:])
y = [0 if label == 'spam' else 1 for label in labels]
y_train, y_test = np.array(y[:5000]), np.array(y[5000:])
모델 생성
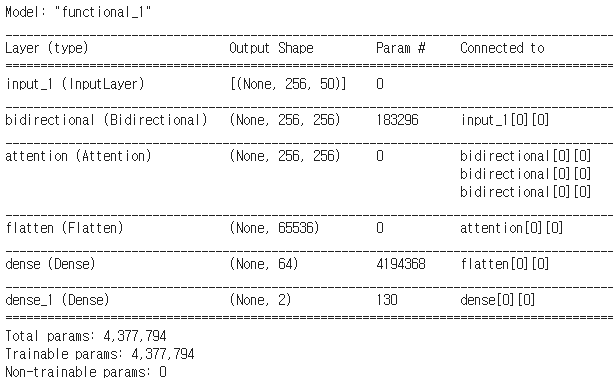
tf.keras.layers.LSTM(128) → 자동으로 LSTM이 다대일로 해서 제일 마지막 결과만 여기 layer에서 출력해준다.
(tf.keras.layers.LSTM(128, return_sequences=True)) → 모든 칸에 대해서 반환
Query밖에 없고 Key와 Value가 필요한 경우 → 세 개를 똑같은걸 넣어줄 때 salf-attention이라고 함
tf.keras.layers.Attention()([lstm_layer, lstm_layer, lstm_layer]) → 원래는 Query, Key, Value 순서대로 넣어야 되는데 지금 Query 하나밖에 없기 때문에 똑같은 거를 넣어줌,, 이거를 salf-attention이라고 함
glove 벡터를 가지고 넣어줬는데 모델 자체에 embedding Layer를 추가할 수 있음! 그럼 vocabulary 아이디만 넣어주고 모델을 활용할 수 있음
Embedding + lstmm + attention 분류 실습 - embedding_layer_lstm_attention_classification.ipynb
from collections import Counter
import urllib.request
import pandas as pd
import numpy as np
import tensorflow as tf
import nltk
from nltk.tokenize import sent_tokenize
from nltk import WordPunctTokenizer
nltk.download('punkt')
# spam classification data loading
urllib.request.urlretrieve("https://raw.githubusercontent.com/mohitgupta-omg/Kaggle-SMS-Spam-Collection-Dataset-/master/spam.csv", filename="spam.csv")
data = pd.read_csv('spam.csv', encoding='latin-1')
data[:5]
vector는 vocab이라는 것을 받아서 vocab에 있으면 vocab에 token ID 만 줄 거임, 없을 때는 vocab에 unk을 넣어서 줄거임
vector가 256보다 작을 때는 <pad>라고 줄 거임
def tokenize(document):
words = []
sentences = sent_tokenize(document) # sentence tokenizing
for sentence in sentences:
words.extend(WordPunctTokenizer().tokenize(sentence)) # word tokenizing
return [word.lower() for word in words] # case normalization
def make_vocab(documents):
word2index = {'<unk>':0, '<pad>':1}
for document in documents:
tokens = tokenize(document)
for token in tokens:
if token not in word2index.keys():
word2index[token] = len(word2index)
return word2index
def get_vector(sentence, vocab):
tokens = tokenize(sentence)
vector = [vocab[token] if token in vocab.keys() else vocab['<unk>'] for token in tokens]
while len(vector) < 256:
vector.append(vocab['<pad>'])
return vector[:256]
vocab을 어떻게 만들었는지 확인, tokenize에 있는 결과 확인, vector 결과 확인
→ get_vector(texts[0], vocab) : 19까지는 ID가 있고 나머지 뒤에 1들은 pad가 채워짐 (256보다 짧기 때문에)
x_train = 5000 * 256
x = [get_vector(text, vocab) for text in texts]
x_train, x_test = np.array(x[:5000]), np.array(x[5000:])
y = [0 if label == 'spam' else 1 for label in labels]
y_train, y_test = np.array(y[:5000]), np.array(y[5000:])
print(x_train.shape)
결과
256개의 token에 대해서 embedding Layer가 붙어야 함
tf.keras.layers.Embedding(len(vocab), 100) → 100 : 사이즈 → 임베딩 테이블이 word2vec랑 똑같이 생김 → 각 vocab에 대해서 100차원짜리 임베딩 테이블 생성
tf.keras.layers.Dropout(0.5)(embedding_table(input_layer)) → 임베딩 테이블에 input이 들어가서 dropout
이렇게 만들면 glove 벡터를 따로 불러서 넣어줄 필요 없이 자체적으로 word2vec 모델을 안에 내장해버림,, → word2vec 모델도 실시간으로 같이 한꺼번에 학습됨! 학습 속도는 느려질 수 있음
!pip install tensorflow_text
!pip install annoy
from annoy import AnnoyIndex
from collections import Counter
import urllib.request
import pandas as pd
import numpy as np
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_text
# spam classification data loading
urllib.request.urlretrieve("https://raw.githubusercontent.com/mohitgupta-omg/Kaggle-SMS-Spam-Collection-Dataset-/master/spam.csv", filename="spam.csv")
data = pd.read_csv('spam.csv', encoding='latin-1')
data[:5]
texts = list(data['v2'])
labels = list(data['v1'])
print(texts[:5])
print(labels[:5])
print(Counter(labels))
# 모델 가져오기
model_url = 'https://tfhub.dev/google/universal-sentence-encoder-multilingual/3'
model = hub.load(model_url)
x = model(texts)
x_train, x_test = np.array(x[:5000]), np.array(x[5000:])
y = [0 if label == 'spam' else 1 for label in labels]
y_train, y_test = np.array(y[:5000]), np.array(y[5000:])
지금 vector_size가 512이기 때문에 AnnoyIndex에 넣어주고 어떤 방법을 활용해서 거리를 구 할 건지 설정 → 'dot' 이 기본
Tree인덱스를 만들고 Tree 인덱스에 5000개를 넣는다.
# annoy indexing
vector_size = 512
index = AnnoyIndex(vector_size, 'dot')
data = []
vectors = model(texts)
for idx in range(len(vectors)):
data.append({'idx':idx, 'text':texts[idx], 'vector':vectors[idx], 'label':labels[idx]})
if idx < 5000: #indexing only 5000 samples, the others will be used for evaluation.
index.add_item(idx, vectors[idx])
index.build(50)
index.save('spam_mail.annoy')
결과
5000부터 나머지 데이터에 대해서 비교
검색하는 방법 : load_index.get_nns_by_vector(data[5000]['vector'], 100) → 100은 몇 개를 검색할지 지정
# evaluation. check accuracy with nearest label
load_index = AnnoyIndex(vector_size, 'dot')
load_index.load('spam_mail.annoy')
result = load_index.get_nns_by_vector(data[5000]['vector'], 100)
print(result)
→ 5000번의 벡터를 넣어서 test를 했을 때 나온 text랑 제일 비슷한 text는 4번 text이다.
→ 라벨은 ham으로 동일하다는 것은 accuracy는 맞다고 할 수 있음
5000개를 다 검사
idx에서 label이랑 result[0]에 있는 label이랑 같으면 count를 올리고, total은 그냥 올림
# evaluation. check accuracy with nearest label
load_index = AnnoyIndex(vector_size, 'dot')
load_index.load('spam_mail.annoy')
count = 0
total = 0
for idx in range(5000, len(data)):
result = load_index.get_nns_by_vector(data[idx]['vector'], 100)
if data[idx]['label'] == data[result[0]]['label']:
count += 1
total += 1
print(count/total)
결과
→ 분류를 굳이 하지 않아도 제일 유사한 문장의 label과 비교를 했을 때 성능이 98점이 나옴
→ 이렇게 검색을 하면 전체 검색보다 훨씬 빠르기 때문에 이런 식으로 서비스 사용하기도 함
왜 100개를 검색을 했는가? Tree를 50개를 생성을 했는데 제대로 동작을 하려면 무조건 트리의 개수보다 많아야 함 → 트리의 두세 배를 검색하게 되면 100개를 검색하면 각 트리에서 두배를 검색을 한 다음 그 100개를 가져와서 100개를 정렬하는 것임,, → 라이브러리 동작 방식이 100개를 검색하는 것과 1개를 검색하는 것이 성능이 너무 달라지기 때문에 100개를 검색을 하게 됨
각 트리에서 나눠져서 동시에 검색을 하기 때문에 Tree의 개수가 많으면 훨씬 빠르고 성능이 좋음
저는 대학 졸업하기 전에 서울로 올라와서 Java 국비지원 학원을 6개월 동안 열심히 다니고, 학원 다니면서 학교를 졸업했는데요. 서울살이가 처음인데 진짜 놀러안가고 열심히 공부했던 것 같아요 ㅋㅋㅋ 생각보다 개발이 너무 재미있어서 그랬네요
원래는 학원 수료하고 난 후 바로 취업을 하려고 준비했으나 개인적인 문제로 몇 개월 동안 본가에서 쉬면서 Python을 공부해보자! 해서 책 사서 혼자 공부했는데요.
우선 파이썬을 공부하게 된 첫번째 이유는!! 파이썬 문법을 처음 봤을 때 간단하고 읽기 쉬워서 그 부분에 매력을 느꼈고, 두 번째 이유는 요즘 파이썬이 국내나 해외에서 많이 떠오르는 언어라는 것을 들었습니다 ㅎㅎ AI 때문인가봐요~
일단 뭐든 배워놓으면 쓸데는 있겠지 라는 생각으로 공부하기 시작했고, 얼마 지나지 않아서 서울시에서 하는 AI 교육을 신청했는데 코딩테스트와 면접을 거치고 2개월 간 교육을 듣게 됐습니다 🫡 굉장히 짧은 시간이었지만 그동안 배운 내용을 이 블로그에 고스란히 담을 수 있던 소중한 시간들이었습니다 🥰
AI 교육을 수료하고 취업준비를 시작한 지 한 달째 면접을 5군데 정도 돌아다녔는데요!!
보통 신입은 코딩을 할줄 안다고 해도 다시 교육을 받기 때문에 기술면접은 깊게 파고들지 않는 것 같아요. (아닐수도) 70% 이상은 인성면접이라고 보면 될 것 같아요. (회사 바이 회사)
면접 복기 했을 때, 많이 받았던 질문들을 뽑아왔습니당
1차 면접 (실무진 면접)
보통 지원한 팀의 실무자분들이 들어와서 이 사람이 우리 팀에 들어오면 잘 섞일 수 있을지에 대해서 물어보기 때문에 성격에 대한 좋은 인상을 심어주는 것이 좋습니다!
수행했던 프로젝트에 대한 질문들이 많기 때문에 프로젝트에 대한 것은 무조건 다시 복기하고 가야해요. 복기 안 하더라도 열심히 했다면 무리 없이 대답할 수 있을거에요.
왜 개발자가 되려고 하는 이유 (비전공자의 경우)
프로젝트 진행 했을 때 힘들었던 점과 극복한 경험
프로젝트 진행 중 의견 충돌이 날 때 해결 방법
내가 지원한 회사가 어떤 일을 하고 어떤 언어를 사용하는지 회사 사이트 들어가서 자세히 공부하는 것을 추천 (회사 지원동기)
내가 제출한 이력서와 자기소개서 내에서 질문 (성격의 장단점, 자신의 강점)
그 외의 이력서에 기재한 기술들에 대한 질문들과 아주 기본적인 지식에 대한 질문들이 있을 수 있음!
2차 면접 (임원 면접)
만약 임원중에 CTO(최고기술경영자)가 있다면 기술 질문이 들어올 수 있습니다. 언제나 방심은 금물
1차 면접에서 기술에 대한 검증은 끝났기 때문에 2차에서는 인성면접 위주로 봅니다.
다른 언어에 대한 두려움이 있는지 (다른 언어를 공부해야 하는 상황이 생길 경우)
5년 또는 10년 후 나의 모습
어떤 개발자가 되고 싶은지
살면서 힘들었던 경험
본인 역량보다 높은 일을 줘서 힘들 경우 어떻게 할 것인지
쉴 때 뭐하는지 (스트레스 핸들링)
형광펜 표시해놓은 부분은 2개 이상의 회사에서 들었던 질문이에요!
제 경험상 모르는 부분은 당당하게 모른다고 말하는 것이 좋은 것 같아요. 이 사람이 알고 있는지 모르고 있는지 다 티가 나기 때문에 솔직하게 말합시다 ㅎㅎ 저는 5초 생각하다가 기억이 잘 안 나면 잘 모르겠습니다. 라고 답변을 했는데 말하고 생각날 때도 많았어요. 그럴 경우에는 마지막에 이야기해도 되니 굳이 지어내지는 않았으면 좋겠습니다~ 오히려 솔직하게 말하는 이런 점이 플러스요인이 될 가능성도 있어요 ㅎㅎ
자기소개는 지원한 직무에 맞게 준비하고, 만약 기술 블로그나 깃허브를 한다면 이력서에 첨부해놓는 게 좋겠죠~ (꾸준히 공부하고 정리해 놓는다는 증거)