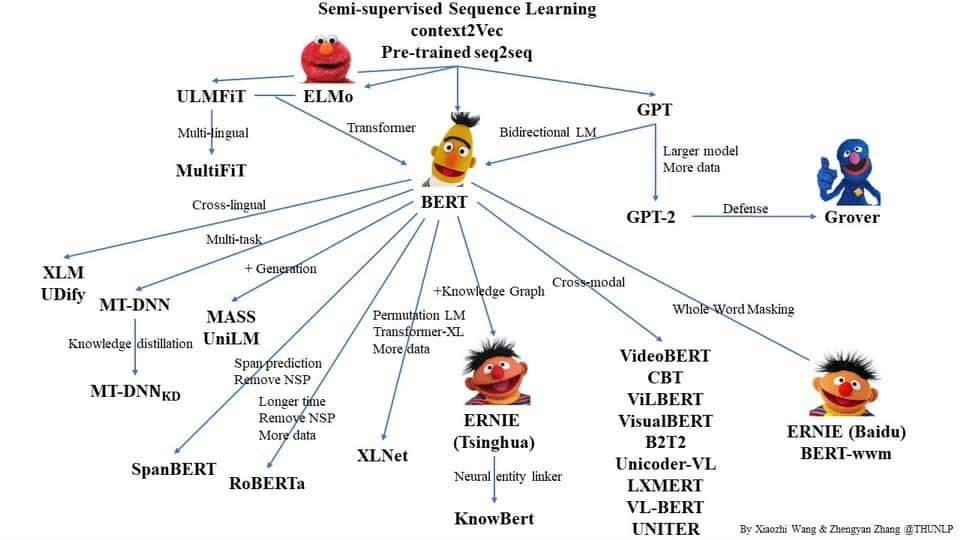
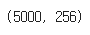Seq2seq model에서는 전체 Context 가 한번에 넘겨가지는 못하고, Attention이 있다고 하더라도 굳이 하나씩 보지말고 전체를 한번에 볼 수 있을까? 해서 만든 것이 Transformers Network
Seq2seq model
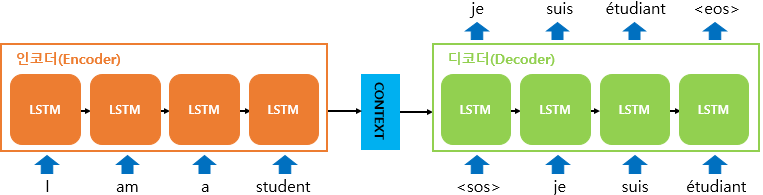
seq2seq 모델은 인코더-디코더 구조로 되어있음
인코더는 입력 시퀀스를 하나의 벡터 표현으로 압축하고, 디코더는 이 벡터 표현을 통해서 출력 시퀀스를 생성
Seq2seq model
그렇다면 Attention으로 RNN을 보정하지 않고, 인코더 디코더안에 Attention을 넣어버린다면?? → 트랜스포머 네트워크
Transformers Network
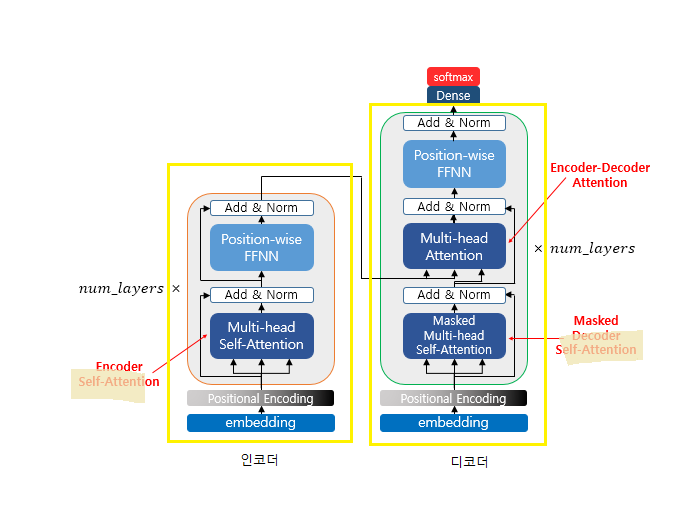
트랜스포머 하나에 인코더와 디코더가 다 들어가있음 → 전체 입력이 트랜스포머 하나에 다 들어감
→ lstm이 느려서 그냥 인코더, 디코더 안에 Attention을 넣어버림
Transformers Network
논문 (Attention is all you need. Vaswani et al. 2017) → 꼭 읽어봐야함
구글 연구 팀이 공개한 딥러닝 아키텍쳐로 뛰어난 성능으로 주목 받았음
GPT, BERT 등의 모델의 기본 모델로 활용되고 있음
→ 인코더에도 디코더에도 임베딩을 전체를 넣어버리고, 인코더에서 애초에 Attention을 활용해서 인코더 전체에 대한 Self-Attention을 보고, 디코더에서도 디코더 전체에 대한 Self-Attention을 알아서 한번 본 다음에 인코더 디코더를 합친 Attention을 가지고 뭔가 하나를 분류하는 거
→ 인코더 디코더를 Layer를 여러개를 쌓을 때 층을 위에 계속 올린다
인코더 : 셀프 어텐션을 거치고 FeedForward 신경망(DNN)을 거쳐서 디코더로 보내줌
ADD : 원래값과 Attention을 거친 값을 넣어서 합한다음 Norm을 해준다 (Overfitting이 줄어듬)
→ 원래 트랜스포머 인코더가 12개가 안에 적층이 쌓여있음! 근데 여기에다가 분류를 할때는 Classification Layer를 하나 추가해주고, 기계독해를 할때는 정답의 위치를 출력하는 Layer 추가해주고, 개체명인식은 각 토큰마다 벡터가 나오기 때문에 각 토큰마다 tagging 을 하도록 Layer를 추가함
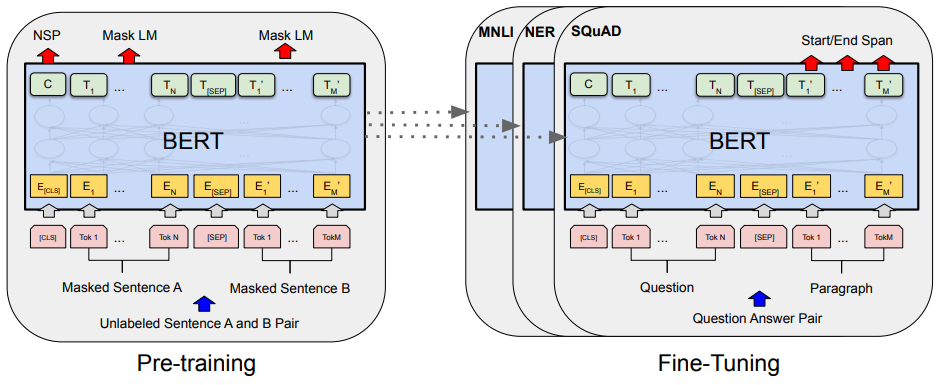
BERT 학습 방식
BERT 이전의 GPT는 기존의 Language Model(언어 모델)을 그대로 학습을 함 → 각 토큰 순서대로 예측을 함
반응형
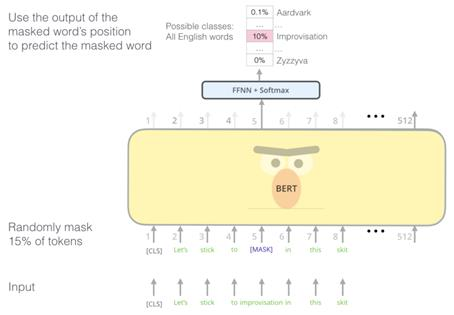
MLM (Masked Language Model)
무슨 토큰이 나와야 할지 분류 !
입력 문장에서 임의로 토큰을 masking 한 후에, 해당 토큰을 맞추는 학습
→ 토큰 하나하나 학습을 안하니까 학습 속도도 빠르고, 인코더를 사용하니까 lstm처럼 이전 토큰에 대한 연산을 기다리지 않아도 된다. lstm 층을 많이 쌓으면 엄청 느린데 BERT는 훨씬 빠르다.
→ 층을 아무리 쌓아도 lstm만큼 느려지지 않음
BERT에서는 Transformer Incoder를 기본적으로 12개 층을 쌓아서 만들었음
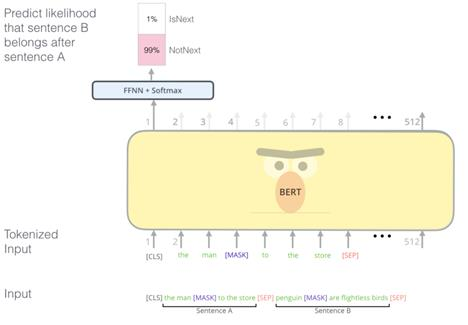
NSP (Next Sentence Prediction)
두 문장이 주어졌을 때, 두 문장의 순서를 예측하는 방식
순서가 맞는지 틀렸는지를 학습함
학습데이터를 문서단위로 입력할 때 문서에서 다음 문장을 가지고 왔을 때는 1, 문장의 순서를 랜덤으로 바꾸고 가지고 올 때는 0으로 학습
→ Bi-classification만 학습을 하기 때문에 학습속도가 빠름
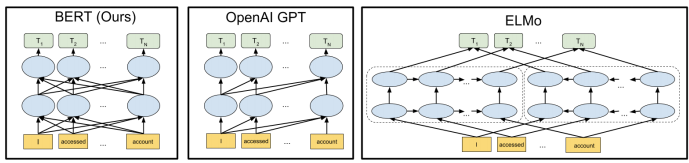
BERT vs GPT vs ELMo
BERT - 구글에서 만듬
MLM학습으로 인하여, 동시에 연산이 가능 → 속도가 빨라짐
GPT - OpenAI에서 만듬
Transformer의 디코더만 사용 - 언어모델 사용
LM(언어모델) 학습으로 인하여 결국 lstm처럼 앞의 토큰 예측이 끝나야 다음 토큰 예측 가능 → BERT보다 속도는 훨씬 느림
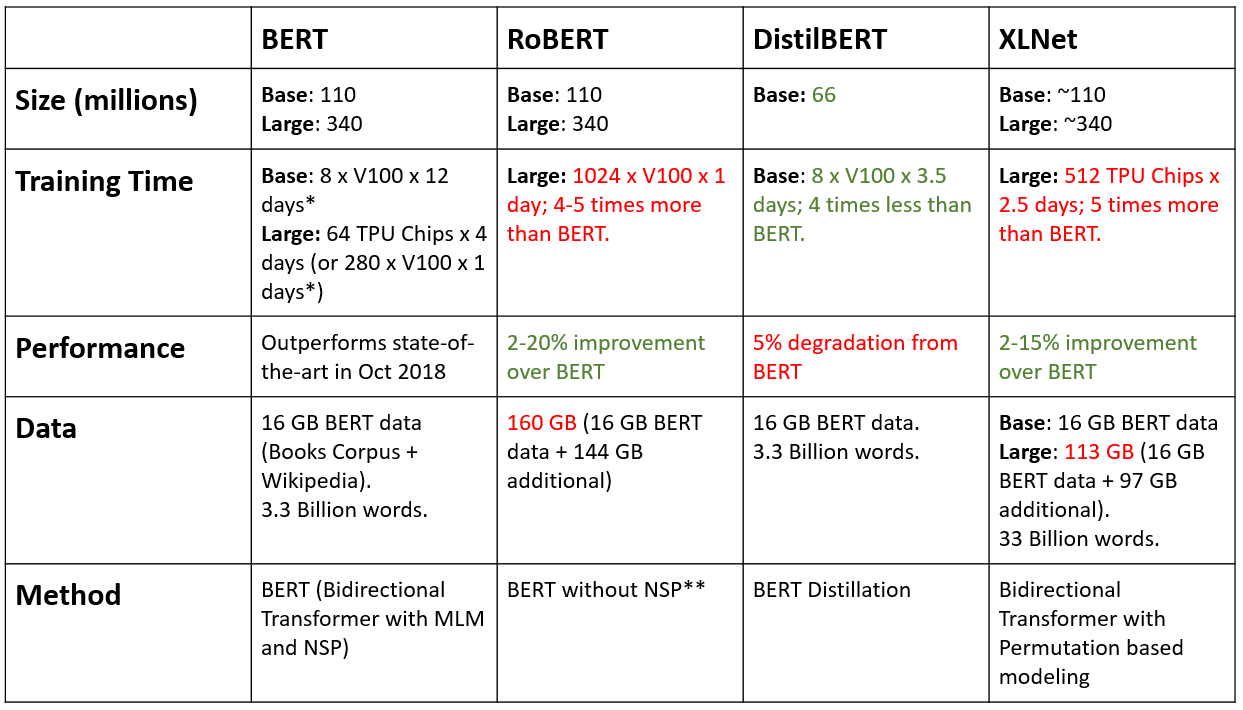
BERT 이후의 모델들
BERT랑 RoBERT랑 차이가 별로 없음, 학습 파라미터 갯수(Size)가 똑같음 → BERT는 GPU를 기준으로 V100을 8대를 12일동안 학습함, RoBERT는 1024개의 GPU를 붙여서 하루만에 학습함 → 학습을 하면서 데이터를 정말 많이 늘렸고, NSP 을 빼고 학습을 함
DistilBERT : BERT에서 뭔가를 없앤것 → BERT가 네트워크 Layer수를 많이 쌓으면서 많이 느린 문제 때문에 Layer를 12개를 사용하는데 Layer를 줄여서 속도를 빠르게 만듬 → 다른거는 똑같음 (모델 사이즈를 줄임 110 → 66) → 성능이 조금 떨어졌지만 속도가 빨라짐
XLNet (permutation??순열??) 학습방법을 바꿈
BERT의 MLM 학습에서는 masking된 토큰이 여러개일 때, 하나의 토큰을 예측할 때 다른 토큰도 masking 되어있다.
XLNet 학습방법 - 처음 앞에 있는 토큰을 예측할 때는 두개의 토큰이 다 masking 되어 있지만 , 뒤의 토큰을 예측할 때는 앞에서 예측한 결과를 받아와서 활용함
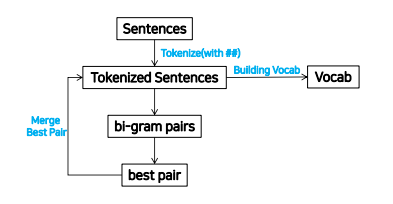
→ 추가된 vocab으로 다시 tokenizing : (aa a b d aa a b a c)
→ 2번의 Iteration을 돌면 : (aa ab d aa ab a c)
→ 3번의 Iteration을 돌면 : (aaab d aaab a c) → vocab은 (a, b, c, d, aa, ab, aaab)
BPE 실습
import _collections
import re
dictionary = {'l o w <end>':5, 'l o w e r <end>':2, 'n e w e s t <end>':6, 'w i d e s t <end>':3}
def get_pair(dictionary):
pairs = _collections.defaultdict(int)
for word, freq in dictionary.items():
symbols = word.split()
for i in range(len(symbols)-1):
pairs[symbols[i], symbols[i+1]] += freq
print('현재 pair:', dict(pairs))
return pairs
def merge_dictionary(pair, v_in):
v_out = {}
bigram = re.escape(' '.join(pair)) # e,s ->'e s' 공백을 확실히 넣어줌
# 앞뒤가 공백인 것을 찾는다 -> 공백제거하고 텍스트찾기
p = re.compile(r'(?<!\S)' + bigram + r'(?!\S)')
for word in v_in:
w_out = p.sub(''.join(pair), word)
v_out[w_out] = v_in[word]
return v_out
epochs = 10
for i in range(epochs):
pairs = get_pair(dictionary)
best = max(pairs, key=pairs.get)
print('best pair:', best[0] + best[1])
new_dictionary = merge_dictionary(best, dictionary)
print('new_dictionary:', new_dictionary)
BERT 모델의 vocab
[PAD] → tokenizing 할 때 모자라는 파?? 에 대해서 padding을 해주는데 padding에 대한 TOKEN
[unused0]
안쓰는것, 나중에 BERT 모델 바꾸고 싶을 때 단어를 추가하고 싶을 때 이걸 바꿔서 단어를 넣으면 그 단어가 tokenizing이 됨
처음에 BERT 모델 학습 할때는 unused는 사용을 안 하고 학습함
캐릭터 단위의 문자가 존재함, 특수문자, 일본어도 있음
어절 첫번째에 오는 것과 중간에 오는 것을 구별하기 위해 ## 을 이용함
ex) lovely → love, ly → love, ##ly로 표현함 (나중에 쉽게 갖다 붙일 수 있게 만듬)
전체 문장에 대한 정보를 한꺼번에 벡터 하나로 만들어서 넘겨주니까 token에서의 정보는 하나도 안 남아있고, 전체 문장에 대한 Context만 넘어감
Attention은 Seq2seq model을 보완하고자 만든 것
Attention
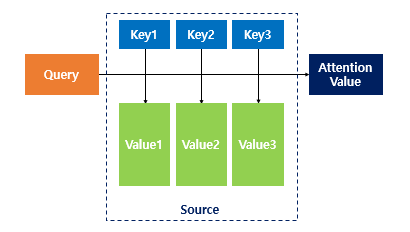
쿼리에 대해서 모든 키와의 유사도를 각각 구하고, 유사도를 키와 맵핑되어 있는 각각의 value에 반영
Query : t 시점의 디코더 셀에서의 은닉 상태
Keys : 모든 시점의 인코더 셀의 은닉 상태
Values : 모든 시점의 인코더 셀의 은닉 상태
→ Attention Value는 Query랑 Key가 들어가서 Value가 곱해져서 다 합쳐진 거임 (먼 소리야ㅎㅎ,,)
Dot-product Attention
매 순간마다 앞에 있던 것을 다 같이 보겠다는 것
기본적으로 곱하기임
→ softmax Layer에서 더 연관이 있는 단어에 weight를 더 많이 줘서 weight들을 전부 더해서 다음에 나올 단어를 예측한다.
그 외의 Attention 종류들
Attention 실습
전에 만들었던 glove_lstm_classification.ipynb 에 attention을 추가해서 만듬
다른 거는 똑같고, model 쪽에 attention 추가
from collections import Counter
import urllib.request
import pandas as pd
import numpy as np
import tensorflow as tf
import nltk
from nltk.tokenize import sent_tokenize
from nltk import WordPunctTokenizer
nltk.download('punkt')
from google.colab import drive
drive.mount('/content/drive')
# spam classification data loading
urllib.request.urlretrieve("https://raw.githubusercontent.com/mohitgupta-omg/Kaggle-SMS-Spam-Collection-Dataset-/master/spam.csv", filename="spam.csv")
data = pd.read_csv('spam.csv', encoding='latin-1')
data[:5]
# glove vector model initialize
glove = {}
with open('/content/drive/My Drive/Colab Notebooks/data/news_sample/glove.6B.50d.txt', 'r', encoding='utf-8') as fr:
for line in fr.readlines():
temp = line.strip().split()
word = temp[0]
vector = temp[1:]
glove[word] = list(map(float, vector))
def tokenize(document):
words = []
sentences = sent_tokenize(document) # sentence tokenizing
for sentence in sentences:
words.extend(WordPunctTokenizer().tokenize(sentence)) # word tokenizing
return [word.lower() for word in words] # case normalization
def get_vector(sentence):
tokens = tokenize(sentence)
vector = [glove[token] if token in glove.keys() else [0]*50 for token in tokens]
while len(vector) < 256:
vector.append([0] * 50)
return vector[:256]
x = [get_vector(text) for text in texts]
x_train, x_test = np.array(x[:5000]), np.array(x[5000:])
y = [0 if label == 'spam' else 1 for label in labels]
y_train, y_test = np.array(y[:5000]), np.array(y[5000:])
반응형
모델 생성
tf.keras.layers.LSTM(128) → 자동으로 LSTM이 다대일로 해서 제일 마지막 결과만 여기 layer에서 출력해준다.
(tf.keras.layers.LSTM(128, return_sequences=True)) → 모든 칸에 대해서 반환
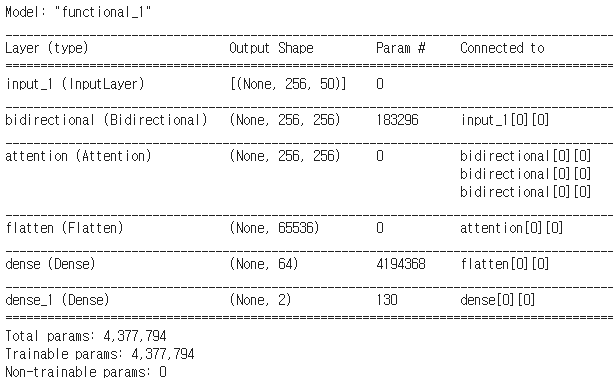
Query밖에 없고 Key와 Value가 필요한 경우 → 세 개를 똑같은걸 넣어줄 때 salf-attention이라고 함
tf.keras.layers.Attention()([lstm_layer, lstm_layer, lstm_layer]) → 원래는 Query, Key, Value 순서대로 넣어야 되는데 지금 Query 하나밖에 없기 때문에 똑같은 거를 넣어줌,, 이거를 salf-attention이라고 함
glove 벡터를 가지고 넣어줬는데 모델 자체에 embedding Layer를 추가할 수 있음! 그럼 vocabulary 아이디만 넣어주고 모델을 활용할 수 있음
Embedding + lstmm + attention 분류 실습 - embedding_layer_lstm_attention_classification.ipynb
from collections import Counter
import urllib.request
import pandas as pd
import numpy as np
import tensorflow as tf
import nltk
from nltk.tokenize import sent_tokenize
from nltk import WordPunctTokenizer
nltk.download('punkt')
# spam classification data loading
urllib.request.urlretrieve("https://raw.githubusercontent.com/mohitgupta-omg/Kaggle-SMS-Spam-Collection-Dataset-/master/spam.csv", filename="spam.csv")
data = pd.read_csv('spam.csv', encoding='latin-1')
data[:5]
vector는 vocab이라는 것을 받아서 vocab에 있으면 vocab에 token ID 만 줄 거임, 없을 때는 vocab에 unk을 넣어서 줄거임
vector가 256보다 작을 때는 <pad>라고 줄 거임
def tokenize(document):
words = []
sentences = sent_tokenize(document) # sentence tokenizing
for sentence in sentences:
words.extend(WordPunctTokenizer().tokenize(sentence)) # word tokenizing
return [word.lower() for word in words] # case normalization
def make_vocab(documents):
word2index = {'<unk>':0, '<pad>':1}
for document in documents:
tokens = tokenize(document)
for token in tokens:
if token not in word2index.keys():
word2index[token] = len(word2index)
return word2index
def get_vector(sentence, vocab):
tokens = tokenize(sentence)
vector = [vocab[token] if token in vocab.keys() else vocab['<unk>'] for token in tokens]
while len(vector) < 256:
vector.append(vocab['<pad>'])
return vector[:256]
vocab을 어떻게 만들었는지 확인, tokenize에 있는 결과 확인, vector 결과 확인
→ get_vector(texts[0], vocab) : 19까지는 ID가 있고 나머지 뒤에 1들은 pad가 채워짐 (256보다 짧기 때문에)
x_train = 5000 * 256
x = [get_vector(text, vocab) for text in texts]
x_train, x_test = np.array(x[:5000]), np.array(x[5000:])
y = [0 if label == 'spam' else 1 for label in labels]
y_train, y_test = np.array(y[:5000]), np.array(y[5000:])
print(x_train.shape)
결과
256개의 token에 대해서 embedding Layer가 붙어야 함
tf.keras.layers.Embedding(len(vocab), 100) → 100 : 사이즈 → 임베딩 테이블이 word2vec랑 똑같이 생김 → 각 vocab에 대해서 100차원짜리 임베딩 테이블 생성
tf.keras.layers.Dropout(0.5)(embedding_table(input_layer)) → 임베딩 테이블에 input이 들어가서 dropout
이렇게 만들면 glove 벡터를 따로 불러서 넣어줄 필요 없이 자체적으로 word2vec 모델을 안에 내장해버림,, → word2vec 모델도 실시간으로 같이 한꺼번에 학습됨! 학습 속도는 느려질 수 있음