반응형
Annoy
- 임베딩 들은 similarity를 직접 구하는 게 많이 사용되는데 특히 추천 같은 경우에서는 다른 사람들의 리스트와 내 리스트가 비슷한 경우에는 제일 비슷한 사람의 리스트에서 내가 보지 않은 리스트들을 추천해줌 (예로 들어 넷플릭스)
- 모든 유저랑 내 기록이랑 similarity 구하는데 유저가 많으면 너무 오래 걸리기 때문에 그런 문제를 해결하기 위해서 나온 Annoy 라이브러리
Nearest Neighbor (근접 이웃)
- 새로운 데이터를 입력 받았을 때, 가장 가까이 있는 것이 무엇이냐를 중심으로 새로운 데이터의

→ 이제까지는 분류모델을 학습을 했는데 각각의 데이터가 있으면 새로 들어온 데이터의 제일 근접한 같은 분류를 하기도 함
Annoy (Approximate Nearest Neighbors Oh Yeah)
- 빠르게 벡터 유사도 검색을 수행할 수 있는 라이브러리
- 정확한 벡터보다는 유사한 벡터를 찾기 때문에 정확도는 조금 낮아질 수 있으나 속도가 매우 빨라짐
- Tree를 활용하여 유사한 벡터를 검색
- Tree를 만드는 과정을 build라고 하며, build 된 Tree는 수정이 불가능
https://github.com/spotify/annoy
Annoy 실습 예제
- 전에 만들었던 use_dnn_classification.ipynb 을 수정해서 만듬
- 모델 생성해주고 정의하는 부분까지 동일함
!pip install tensorflow_text
!pip install annoy
from annoy import AnnoyIndex
from collections import Counter
import urllib.request
import pandas as pd
import numpy as np
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_text# spam classification data loading
urllib.request.urlretrieve("https://raw.githubusercontent.com/mohitgupta-omg/Kaggle-SMS-Spam-Collection-Dataset-/master/spam.csv", filename="spam.csv")
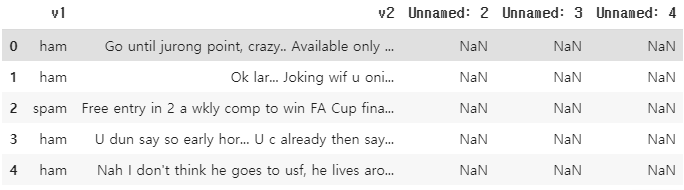
data = pd.read_csv('spam.csv', encoding='latin-1')
data[:5]

texts = list(data['v2'])
labels = list(data['v1'])
print(texts[:5])
print(labels[:5])
print(Counter(labels))
# 모델 가져오기
model_url = 'https://tfhub.dev/google/universal-sentence-encoder-multilingual/3'
model = hub.load(model_url)x = model(texts)
x_train, x_test = np.array(x[:5000]), np.array(x[5000:])
y = [0 if label == 'spam' else 1 for label in labels]
y_train, y_test = np.array(y[:5000]), np.array(y[5000:])
반응형
- 지금 vector_size가 512이기 때문에 AnnoyIndex에 넣어주고 어떤 방법을 활용해서 거리를 구 할 건지 설정 → 'dot' 이 기본
- Tree인덱스를 만들고 Tree 인덱스에 5000개를 넣는다.
# annoy indexing
vector_size = 512
index = AnnoyIndex(vector_size, 'dot')
data = []
vectors = model(texts)
for idx in range(len(vectors)):
data.append({'idx':idx, 'text':texts[idx], 'vector':vectors[idx], 'label':labels[idx]})
if idx < 5000: #indexing only 5000 samples, the others will be used for evaluation.
index.add_item(idx, vectors[idx])
index.build(50)
index.save('spam_mail.annoy')
- 5000부터 나머지 데이터에 대해서 비교
- 검색하는 방법 : load_index.get_nns_by_vector(data[5000]['vector'], 100)
→ 100은 몇 개를 검색할지 지정
- 검색하는 방법 : load_index.get_nns_by_vector(data[5000]['vector'], 100)
# evaluation. check accuracy with nearest label
load_index = AnnoyIndex(vector_size, 'dot')
load_index.load('spam_mail.annoy')
result = load_index.get_nns_by_vector(data[5000]['vector'], 100)
print(result)

→ 5000번에 대한 데이터에서 제일 가까운 순서대로 100개 출력
- 4번 데이터의 text와 label , 5000번 데이터의 text와 label 확인
print(data[4]['text'], data[4]['label'])
print(data[5000]['text'], data[5000]['label'])
→ 5000번의 벡터를 넣어서 test를 했을 때 나온 text랑 제일 비슷한 text는 4번 text이다.
→ 라벨은 ham으로 동일하다는 것은 accuracy는 맞다고 할 수 있음
- 5000개를 다 검사
- idx에서 label이랑 result[0]에 있는 label이랑 같으면 count를 올리고, total은 그냥 올림
# evaluation. check accuracy with nearest label
load_index = AnnoyIndex(vector_size, 'dot')
load_index.load('spam_mail.annoy')
count = 0
total = 0
for idx in range(5000, len(data)):
result = load_index.get_nns_by_vector(data[idx]['vector'], 100)
if data[idx]['label'] == data[result[0]]['label']:
count += 1
total += 1
print(count/total)
→ 분류를 굳이 하지 않아도 제일 유사한 문장의 label과 비교를 했을 때 성능이 98점이 나옴
→ 이렇게 검색을 하면 전체 검색보다 훨씬 빠르기 때문에 이런 식으로 서비스 사용하기도 함
왜 100개를 검색을 했는가?
Tree를 50개를 생성을 했는데 제대로 동작을 하려면 무조건 트리의 개수보다 많아야 함
→ 트리의 두세 배를 검색하게 되면 100개를 검색하면 각 트리에서 두배를 검색을 한 다음 그 100개를 가져와서 100개를 정렬하는 것임,,
→ 라이브러리 동작 방식이 100개를 검색하는 것과 1개를 검색하는 것이 성능이 너무 달라지기 때문에 100개를 검색을 하게 됨
각 트리에서 나눠져서 동시에 검색을 하기 때문에 Tree의 개수가 많으면 훨씬 빠르고 성능이 좋음
반응형
'AI > 자연어처리' 카테고리의 다른 글
| [AI] StanfordNLP, Khaiii (Kakao Hangul Analyzer III) 설명 및 예제 (0) | 2020.12.18 |
|---|---|
| [AI] 어텐션 메커니즘(Attention Mechanism)이란? - 개념 및 예제 (0) | 2020.12.17 |
| [AI] Embedding + LSTM 분류 예제 (0) | 2020.12.16 |
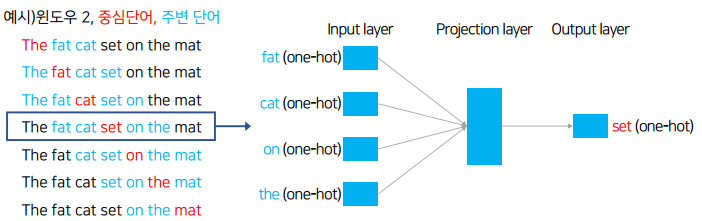
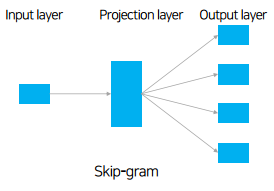
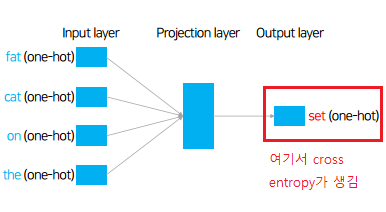
| [AI] Word2Vec, GloVe, FastText, ELMo 기본 설명 및 실습 (0) | 2020.12.16 |
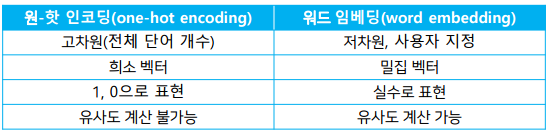
| [AI] 단어표현방법 (Bag of Words, Word2Vec, One-hot Vector 등) 설명 및 실습 (1) | 2020.12.15 |